Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)


Data Management has become a vital component for businesses across all sectors today. Whether you operate in banking and financial management, manufacturing, or data analytics, the universal need for data underscores its importance in all fields.
Businesses rely heavily on accurate data to make better decisions about their profitability. However, inaccurate data can become a recipe for disaster.
Data extraction and abstraction can make data management efficient for organizations. They can easily filter through the data, sort it out the way they wish, interpret it quickly, and promptly make decisions based on the analysis.
This article will delve deep into data extraction and data abstraction and explore the differences between the two. It will also highlight their characteristics on various parameters, which will help you decide which process is most desirable based on your requirements.

Data extraction is the process of pulling out raw data from single or multiple sources to analyze the information in a customized way. A few of the many sources of data extraction could be a scanned PDF document, Excel file, or handwritten documents.
Usually, you can extract information such as invoices, customer profile data sets, form-filled data, financial information, and so on from documents during the data extraction process.
Let’s take an example of a financial institution that wants to extract data from various loan applications filled in by different customers.

Data Abstraction is a process that hides the complexities of data processing and storage from the user. The user can navigate through an easy-to-use interface to achieve their desired datasets.
There are several advantages of using the data abstraction process. Some of them are as follows:
Data abstraction solution provides a summarized view without understanding how the data is extracted from it. By eliminating the need to understand the process, it focuses on delivering excellent performance in terms of the results requested by the user.
.png)
Both data extraction and data abstraction have advantages and disadvantages. The data extraction process is adaptable and flexible but does not hide the method in which it takes place. Data abstraction makes it easy for end users to filter out and extract data but has limited functionality in terms of rule settings.
The end objective of why you need to extract and store data matters the most in deciding which approach to take. Data management is essential for all enterprises today, but their approach depends a lot on their goal with the data they have in hand.
Apart from the end objective, there are a few other factors to consider before deciding between data extraction and data abstraction processes.
What kind of data do you want to extract? What is the data source, and how must it be presented? Answering such questions can help define the scope of work and determine the process to be implemented for database management.
Another factor to remember before you choose a data extraction or data abstraction process is software integration.
Another factor to consider before choosing one of two options for the database management process is how the data will be used and for what purpose.
The critical factor in deciding between a data extraction or data abstraction process also depends on the type of dataset you are working on.
Below is a comparison of data extraction and data abstraction processes based on various standard parameters.
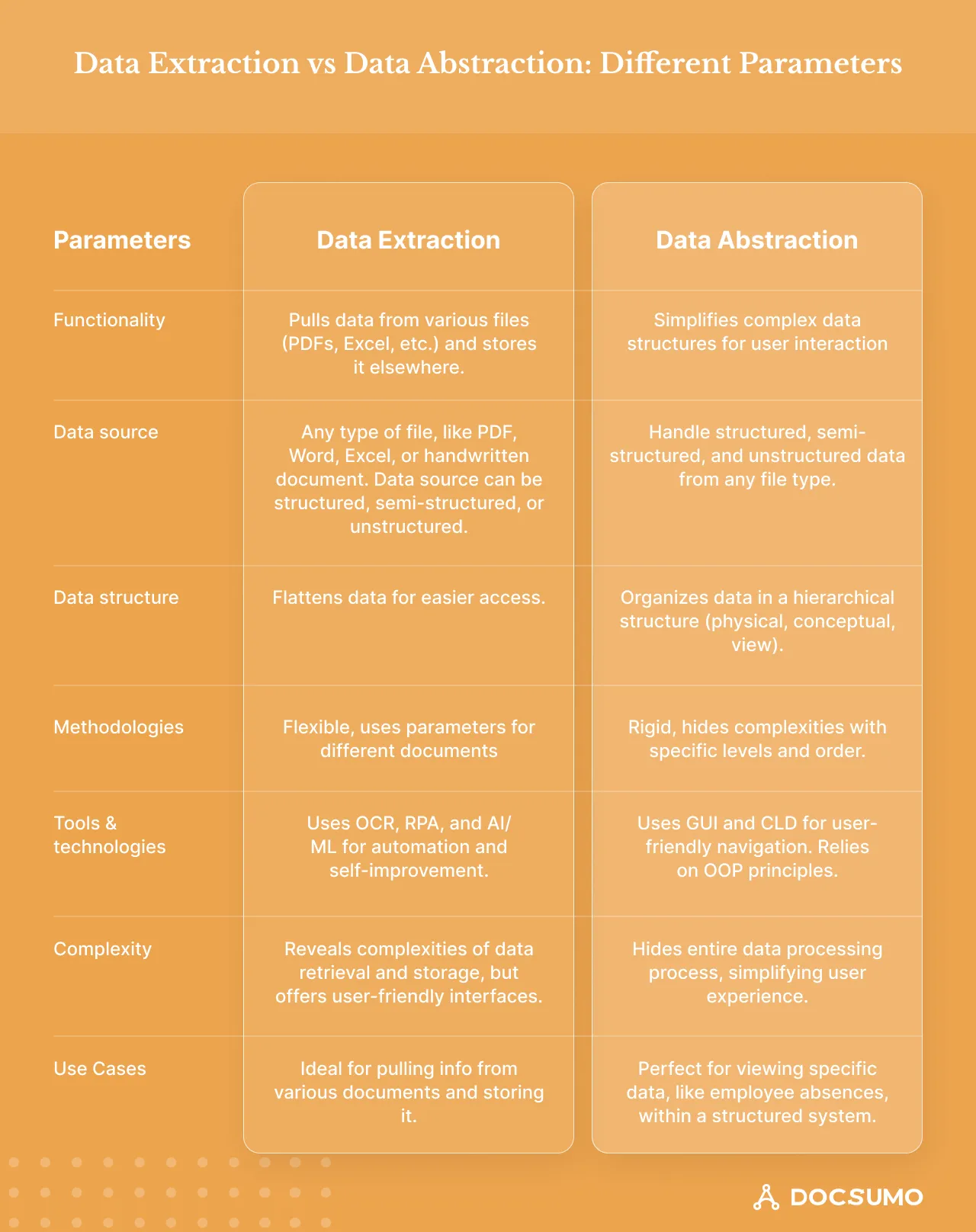
Database management is a highly complex process. Filtering, sorting, interpreting, and storing information is a massive task you cannot achieve by implementing one method alone.
Data extraction and data abstraction processes complement each other rather than compete with each other. Both these processes can be implemented simultaneously depending on the requirement, use case, and objective.
If an organization has to manage large amounts of raw data, it becomes effective and efficient if it enforces multiple database management strategies. Therefore, it is highly recommended that both processes be used to get the best out of both and become more adaptable to innovative methods of managing data.
Docsumo is a leading data extraction and data management solution that can be easily integrated with any existing solution. With up to 80% data accuracy, you implement a solution that can extract and store data end-to-end with minimal human intervention.
Docsumo can self-learn and improve its accuracy using artificial intelligence and machine learning techniques after processing several documents.
Schedule a Docsumo demo or talk to our expert to learn more about Docsumo.


If you want to know the data extraction and storage process, you should opt for data extraction. If your goal is to hide the complexities of the data process and require just the output, a data abstraction process is recommended.
Yes, the data abstraction process occurs sequentially and can improve the overall data extraction process.
Yes, there can be scenarios where data extraction and data abstraction can be used together to extract and process data.


