Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)


Tables that look clean and organized in a PDF often become a tangled mess when copied into Excel. And the manual retyping required is a huge time-sink, leaving little room for the analysis and reporting that drives critical decisions.
This comprehensive guide explores the pressing need for efficient data extraction and examines how it unlocks opportunities for deeper analysis, smarter decision-making, and streamlined workflows.
Converting data from PDF to Excel offers efficient access to valuable business information, enabling enhanced analysis and decision-making. This time-efficient process provides a quicker alternative to manual extraction and unlocking hidden insights for strategic planning and optimization.
The efficient and accurate data extraction is vital for maintaining data integrity, ensuring downstream ETL (Extract, Transform, Load) stages can effectively utilize the data.
PDF to Excel data extraction is crucial across professional settings, enhancing data analysis, reporting, and decision-making. An efficient workflow saves time for professionals in finance, healthcare, and legal sectors, boosting overall productivity.
Excel's structured format ensures precision in data handling, which is particularly beneficial for finance, research, and analytics. Data extraction organizes information in manufacturing and supply chains, providing decision-makers with valuable insights for strategic planning.
Accurate extraction ensures regulatory compliance and seamless reporting in sectors like healthcare and finance. Legal contexts benefit from PDF extraction, transforming unstructured legal documents into organized data for efficient retrieval and analysis.
Convert PDF to Excel Free Using Our Free Tool
Data extraction from PDF to Excel poses several challenges that organizations and teams commonly encounter.
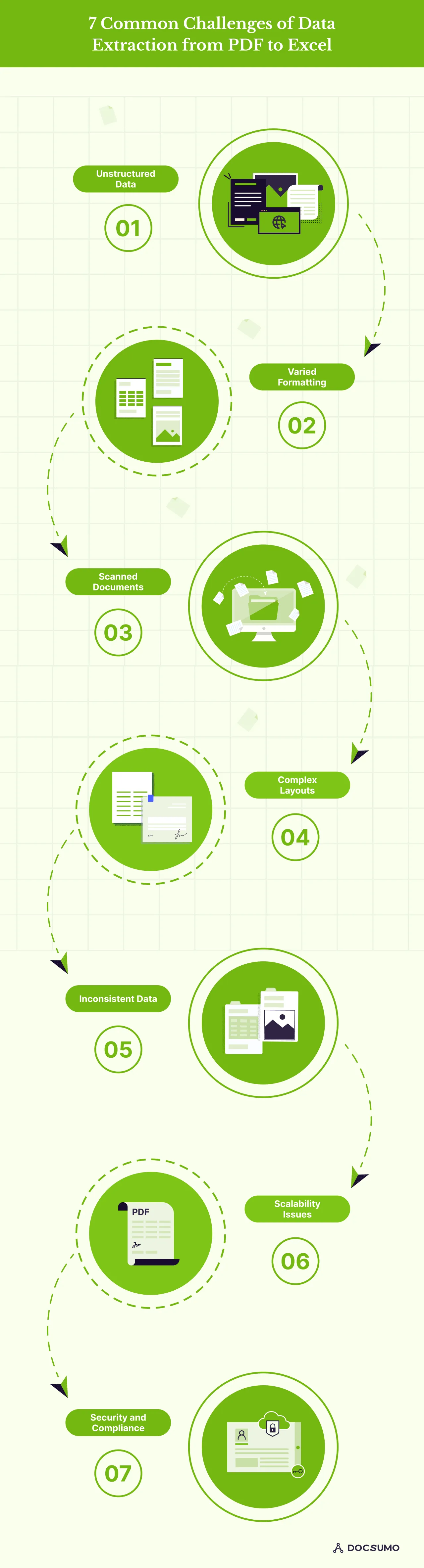
Gaining insight into the challenges is vital for selecting the optimal conversion approach and pinpointing the most suitable tools and techniques for processing data in Excel post-conversion. Here are some common data extraction challenges from PDFs:
PDF documents are often designed for human readability rather than machine processing. Hence, unstructured data is difficult to extract and organize into a structured format like Excel.
PDFs can have a wide range of formatting styles, layouts, and structures, making it challenging to develop a one-size-fits-all solution for data extraction. This can lead to inconsistencies and errors in the extracted data.
Many PDF files are created by scanning physical documents, resulting in image-based content rather than editable text. Extracting data from these scanned PDFs requires advanced optical character recognition (OCR) capabilities, which can be prone to errors.
Some PDF documents have complex multi-column layouts, tables, and other design elements that need to be clarified for traditional data extraction methods. Accurately identifying and extracting data from these intricate formats is a significant challenge.
PDFs often need consistent data regarding units, formatting, and naming conventions. Reconciling these variations and ensuring data integrity is crucial for practical data analysis and reporting.
As the volume of PDF files and the complexity of the data within them increases, manual or basic extraction methods quickly become inefficient and unsustainable. Scaling the data extraction process is a common hurdle for organizations.
Many businesses operate in highly regulated industries where data privacy and security are paramount. Extracting sensitive information from PDFs while complying with industry standards and regulations can be daunting.
Preparing PDFs for data extraction can minimize the challenges and increase the accuracy of the extracted data. Here are some tips for optimizing PDFs for data extraction:

.png)
Take a look at some step-by-step to set up a data extraction from PDF to Excel, including:
Many tools exist, but consider one with intelligent OCR (Optical Character Recognition) like Docsumo. This technology automatically captures data from your PDFs.
Upload a sample PDF and highlight the specific data points you want to extract. This "training" helps Docsumo improve accuracy for future data extractions from similar PDFs.

Use Docsumo's advanced automated data extraction settings to fine-tune the extraction process. Specify data formats, apply filters, and configure other settings to ensure accurate and consistent data extraction.
After the extraction process, Docsumo presents the extracted data in a structured format. Review the data and make any necessary corrections before approving it to various formats like CSV, Excel, JSON, and more.
Docsumo offers automation capabilities for large document sets to streamline data extraction. Set up automated workflows that trigger data extraction based on specific events or schedules.
Integrate Docsumo with popular tools and platforms like Zapier, Microsoft Power Automate, and more, enabling efficient data processing and analysis within your existing workflows.
After the data is extracted from PDFs to Excel using Docsumo, there are several important steps and considerations to ensure data integrity, security, and effective utilization of the extracted data.

Here are the best practices for managing extracted data from PDF to Excel:
Data extraction from PDF files is critical for businesses dealing with large amounts of data. However, it can be challenging due to the nature of the unstructured data, formatting variations, and the presence of scanned documents.
By leveraging the right tools and strategies, organizations can streamline their data workflows, unlock valuable insights, and drive decision-making like never before.
In this article, we have discussed the importance of data extraction from PDF to Excel and the common challenges of data extraction from PDF to Excel. Preparing PDFs for data extraction is a step-by-step guide to extract data from PDF to Excel.
Seamlessly integrating data from PDFs into Excel spreadsheets empowers users to analyze, visualize, and act on information with incredible speed and accuracy. Automating the manual data entry saves time, reduces errors, and allows teams to focus on more strategic initiatives.
Docsumo helps extract data instantly by identifying and pulling data, cutting processing costs by up to 80%, and speeding up document timelines via precise unstructured data analysis.
Intelligent data extraction can train the models to adapt and capture valuable data from tables in your documents.
If you want an intelligent way to process documents, signup for a free 14-day trial.


Here are some ways to ensure accuracy. Use a reliable tool with high OCR accuracy (like Docsumo). Always review and correct extracted data. Test with a sample PDF before processing large batches. Use clear, well-formatted PDFs.
Standardize your PDFs for easier data pattern recognition. Define clear extraction rules for data points and formatting. Start small, automate for a few PDFs, then scale gradually. Monitor automated workflows and adjust settings if needed.
Limited free trials exist, often with restricted features. Open-source libraries require technical expertise. Consider long-term cost-benefit: paid tools can save time in the long run.


