Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)


Raw data is like a treasure locked in a chest—full of potential but inaccessible. Companies can become data-driven, agile, and profitable by extracting this treasure.
Not only does data help drive customer-centric marketing initiatives and strategic business decisions, it also increases the competitive advantage, reduces risk exposure, and lowers costs by facilitating informed resource allocation.
Data extraction is the key that unlocks this potential, opening up a world of possibilities for businesses. This is why data-driven enterprises focus on growth and trust data to back their decisions. Unsurprisingly, 49.1% of companies manage data as a business asset today. According to Statista, 48.1% have created a data-driven organization, and about 77% of businesses drive innovation with data.
This article will discuss different data extraction methods to leverage data and uncover hidden insights. It will also discuss the challenges and best practices for extracting data from structured, semi-structured, and unstructured data.

Data extraction is simply retrieving information from various sources, such as documents, files, customer profiles, websites, etc., to process and analyze hidden insights, trends, and patterns.
Businesses generate huge amounts of data from different channels, such as social media interactions, website customer interactions, operational processes, and financial transactions. The raw data extracted from these sources works as the raw material for analysis and ultimately drives business and strategic decisions of different departments.
The extracted data is transformed into usable formats, which help leverage insights to enhance operational efficiency and a business's financial health, combat security issues, bypass bottlenecks in growth drivers, and identify customer and market trends.
These insights ultimately lead to optimized operations, targeted marketing campaigns, better budget and resource allocation, and growth. This is why data is so important.
However, different businesses generate different data types, which serve different purposes for different industries. For each data type, the extraction method also varies.
For example, data extraction in the insurance industry helps with risk assessment, streamlining insurance processes, and identifying fraudulent activities. You would want to target data extraction for these purposes here.
Similarly, data extraction in logistics and supply chains helps in inventory optimization. In financial services, it helps assess creditworthiness and risk management.
Some other use cases of data extraction for different industries are:
Now that we understand data extraction and why it is important, let’s explore the types of data extraction.
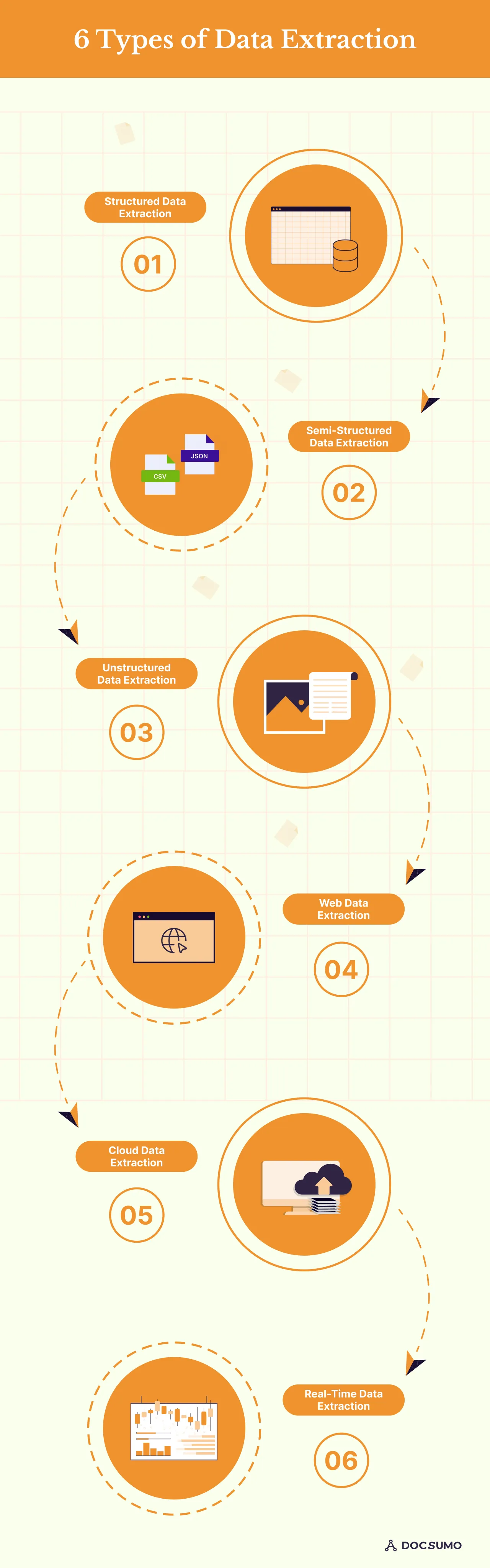
As the name suggests, this involves pulling data stored in structured data formats like databases and spreadsheets. The formats and schema are predefined in these sources and are organized in databases, where data is stored in tabular formats with clearly defined fields. Because the data is structured, it is easy to search, categorize, or reorder and extract data from structured data. Some examples of structured data include spreadsheets, SQL databases, etc.
Structured data extraction involves querying the database using SQL or other query language to pull datasets based on predefined criteria. It requires crafting precise queries to extract the exact data.
For example, market research analysts can use structured data extraction to gather customer details from data stored in internal databases. You can export specific fields from user data stored in an SQL database, with information on demographics, product ratings, contact details, etc. Using SQL queries, you can extract data about customers within a particular age group in a particular region who rated the product below average.
Semi-structured data extraction involves pulling data from sources that do not adhere to tabular formats like structured data but exhibit some organizational properties. These provide some level of organization but are not as strict as the database schema. They have no predefined data model and have irregular structures.
XML, JSON, and CSV files exhibit some level of organization but are not structured. Emails are another example of semi-structured data, which contains various metadata fields. Due to its heterogeneous and flexible nature, semi-structured data requires more complex parsing and processing techniques than structured data extraction.
They often include nested structures and use techniques like XML parsing, regular expressions, NLP, and text mining algorithms.
For example, email parsing libraries can extract customer feedback from emails.
Unstructured data extraction involves extracting information from unstructured data and unorganized data sources like emails, social media posts, PDFs, text files, scanned images, etc. The lack of any structure makes it difficult to extract the required data. It does not conform to a specific schema, making processing and retrieving information complex.
Unstructured data extraction requires a more sophisticated processing technique, such as NLP, text and image recognition, OCR, and text mining algorithms, for identifying patterns.
For example, extracting patient information from medical records in healthcare can help in treatment planning and proactive diagnosis.
Also known as web scraping, web data extraction involves extracting data from web pages. It uses specialized tools and scripts to navigate the web pages, locate the data elements, and extract the data.
Web data extraction is used by businesses to gather data from various online sources, such as websites, news portals, social media platforms, and online government databases.
The web scraping tools usually deploy bots to sift through databases and retrieve information. These bots are customized to recognize unique HTML site structures, extract and transform information, store scraped data, and extract data from APIs.
Web scraping can be used for price comparison by scraping competitor pricing and optimizing pricing strategies.
As the name suggests, cloud data extraction extracts data from cloud services and platforms to access data stored in cloud environments like AWS S3 buckets, Google Cloud Storage, Microsoft Azure, and others.
These sources may contain structured or unstructured data in different formats and schemas. To extract data from the cloud, ETL pipelines (extract, transform, load) and tools are often integrated with the cloud service provider’s APIs and SDKs for data retrieval.
For example, cloud data extraction from Meta and Google Ads can be used to measure the ROI of marketing campaigns for budget optimization.
This extraction involves capturing and processing data as it is generated to provide instant access to insights. This method is essential for scenarios that require continuous monitoring, like the stock market. This extraction allows data extraction in real-time and is essential for identifying issues, maximizing revenue, and optimizing user experience. It is used in alerting and monitoring systems and often uses streaming ETL and APIs to facilitate data extraction.
The stock market is one of the best examples of real-time data extraction, which helps trading platforms access real-time market data and analyze it for trading opportunities.
Data extraction is crucial, but choosing the wrong type for your business will make you lose out on a big opportunity–deriving effective and accurate insights. Different data extraction offers different benefits and is suitable for unique use cases. Here’s how to choose the right data extraction type for your business:
To understand your need correctly, answer these questions:
.png)
Let’s look at the challenges faced in data extraction. These challenges hinder the effectiveness of data extraction efforts and also impact its reliability:
Now that we know the data extraction challenges, addressing them requires implementing the best practices and leveraging tools and technologies for accurate and efficient data extraction.
Regular data validation checks correct the inconsistencies and identify errors and missing values. Implement a cleaning process to standardize the data format and remove duplicates.
Leverage AI-powered tools like Docsumo to streamline data extraction from various unstructured documents accurately. Some of the key functionalities offered by Docsumo are:
Encourage the use of AI and automation in the data extraction process, wherever possible, to reduce the scope of manual errors and trigger alerts in case of breaches or security threats.
With tools like Docsumo, security, and compliance concerns are addressed automatically as they ensure adherence to regulations and data protection measures. If you do not have a robust tool, implement robust encryption, access controls, and authentication mechanisms to protect data.
Monitor and track the extraction processes to detect anomalies and regularly maintain the systems, such as updating extraction scripts, performance optimization, and issue resolution for smooth operations.
Maintain comprehensive documentation of the extraction process, methods, data sources, quality assurances, and transformations applied. This facilitates traceability and auditability to maintain consistency and standardization.
Choosing the right types of data extraction is critical to empower your data strategy. It drives data-backed decision-making, which is the backbone of modern businesses. The key to selecting the right method depends on your requirements and how accurately the method retrieves the desired data.
Docsumo is an ideal choice for organizations seeking accurate data extraction tools. Powered by AI, Docsumo offers 99% document data accuracy, touchless processing, reduction in operational costs, and 10X efficiency.
To get started with intelligent document processing, talk to Docsumo experts.




