Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)
Overcome image quality issues in data extraction by leveraging advanced preprocessing techniques and robust machine learning algorithms. Read the blog to learn about proven strategies, essential tools, and technologies to enhance accuracy.


Difficulties in extracting graphic data, such as low resolution, noise, blurriness, and distortion of figures, can lead to suboptimal decision-making, decreased productivity, and increased manual intervention, which, in turn, can affect your operations.
These image quality issues can harm businesses striving to maintain high operational standards.
We’ve compiled a list of practical strategies, tools, and techniques to help you overcome image quality issues in data extraction.
Image quality encompasses pixel density, sharpness, color gamut, and freedom from geometric distortion and noise. In other words, it is based on how much an image represents visual information.
In data extraction, an image’s quality directly affects the process’s efficiency and the reliability of the results. In high-quality images, the sharpness of the image allows the extraction algorithm to easily distinguish between texts, numbers, or any other required data. On the other hand, poor-quality images bring uncertainties and ambiguities, which contribute to errors and inaccuracies in the extracted data.
Docsumo ensures high accuracy rates in data extraction by reliably capturing and processing data from various document formats, including scanned images, PDFs, and digital documents.
Read more: A comprehensive guide to image optimization for data extraction
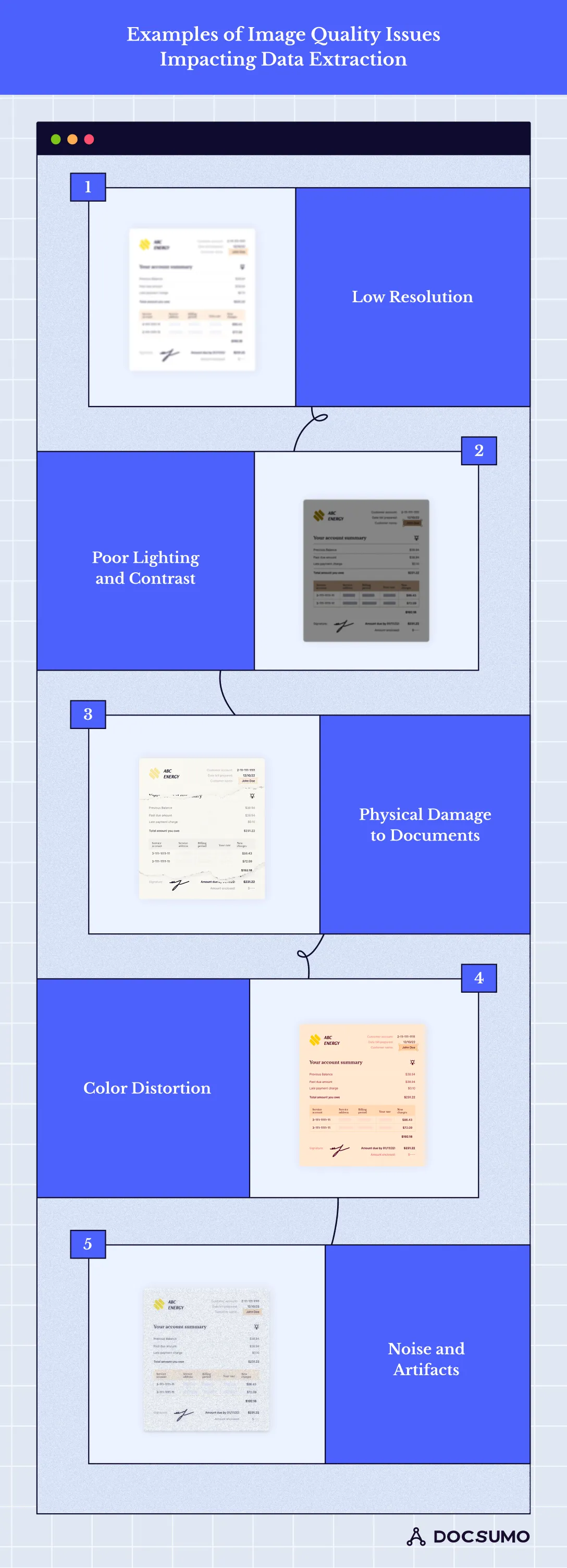
Resolution refers to the number of pixels per unit area in an image. Higher-resolution images contain more pixels, resulting in greater detail and clarity. When an image is low quality, the details cannot be well-rendered, which poses problems when performing tasks such as extracting small texts or patterns.
In healthcare, using low-resolution scans of handwritten prescriptions and medical forms to extract patient data can lead to mistakes and inaccuracies in patients’ diagnoses and treatment plans.
Poor lighting and contrast, especially in images, may make reading written text or details on the extracted data difficult.
For instance, while extracting data in the financial sector, receipts taken in low light have low contrast, which may be inaccurate when capturing transaction details required in reporting expenses.
Any physical damage, such as a tear, crease, or spot, affects the image’s readability and data extraction from graphic images and documents.
Physical damage to documents affects data accuracy when extracting data from logistics, as delivery information described in shipping documents can lead to a delay in the shipment or incorrect stock checking.
Color distortion in an image impacts the shape, clarity, and look of the text and any visual object, which challenges database extraction algorithms.
For instance, in data extracting in healthcare, errors in color during medical images or chart scanning could distort diagnostic information and complicate patients’ treatment.
Noise and image artifacts, such as speckles or scratches, will likely obscure text and details, impacting data extraction accuracy. Furthermore, if an image of a machined part contains noise or artifacts, it becomes challenging for quality control systems to accurately detect surface imperfections or dimensional inaccuracies.
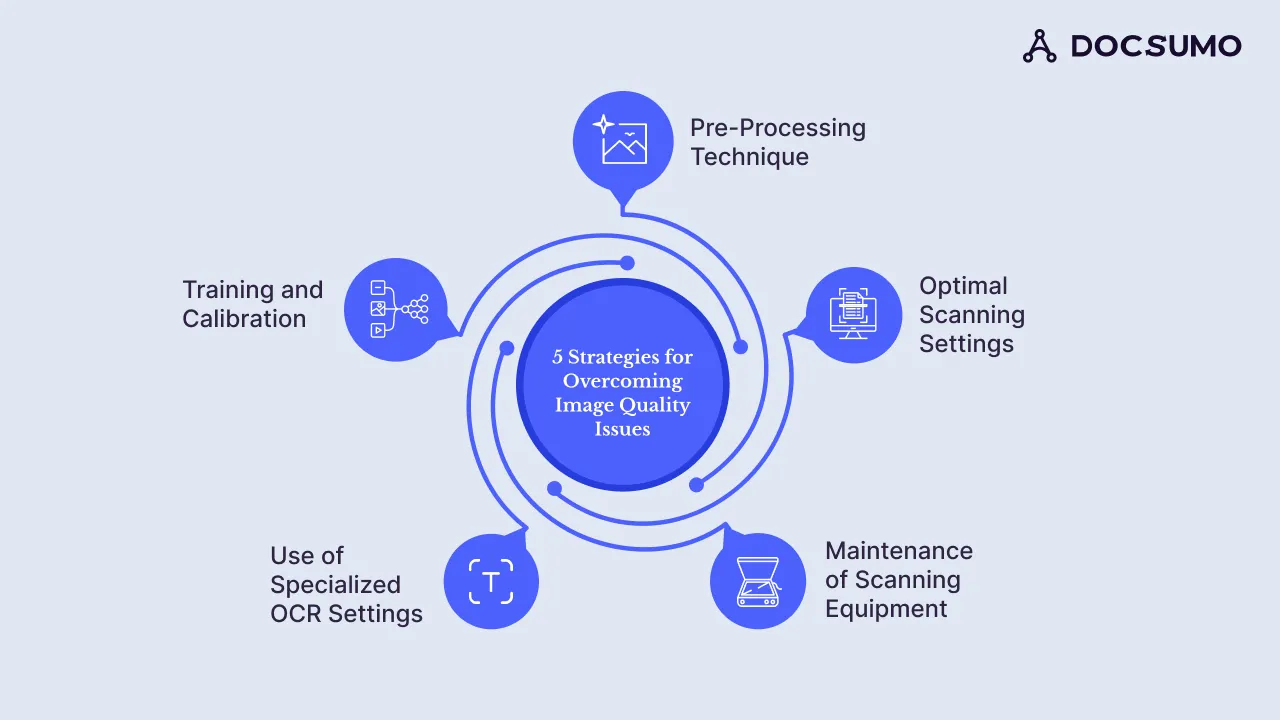
The first step to maintaining consistent image quality and extraction accuracy is to train your full-time employees (FTE) in scanning and data extraction methods.
Educate them on scanning methods, image management, calibration, and combining manual adjustments (correcting scanner settings) with software (image enhancement tools) for accurate image capture and processing.
.png)
Manual efforts to enhance image quality are time-consuming and error-prone. Advanced image enhancement tools use image processing features and AI and deep learning improvements that allow them to correct common errors in the quality of received images and to adjust them for further data recognition.
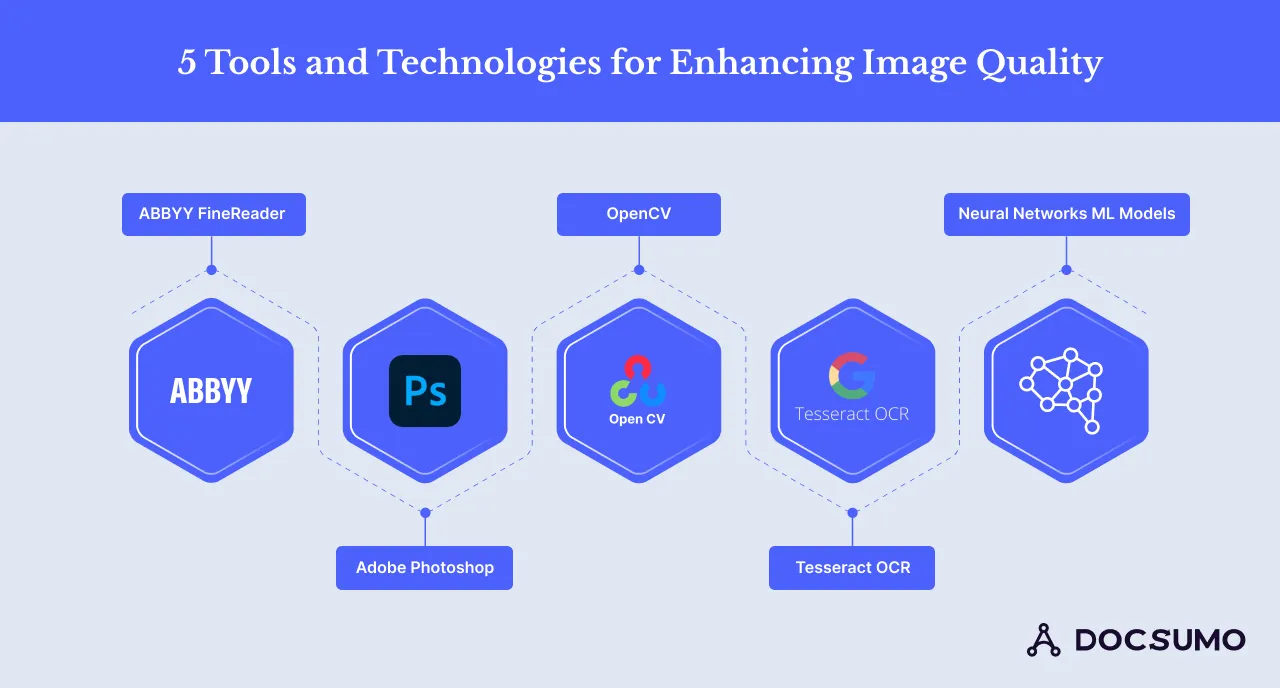
Adobe Photoshop is widely used for image editing and manipulation. It has numerous features and options that help boost the quality of the image, such as sharpness, noise elimination, and hue adjustment.
Operations, IT, and underwriting teams use Photoshop to rectify image quality and legibility to enhance images before data extraction.
In addition to its robust text recognition capabilities, ABBYY FineReader offers features such as image preprocessing and enhancement filters.
You can automatically correct common image quality issues, such as blurriness and noise, before extracting text, ensuring more precise and accurate OCR results.
For a more efficient solution for OCR tasks, consider Docsumo, an efficient ABBYY FlexiCapture alternative. While both platforms offer OCR capabilities, Docsumo stands out with pre-trained APIs, easy processing, numerous integrations, and affordable and transparent pricing.
Here’s how Docsumo stands apart:
OpenCV (Open Source Computer Vision Library) is an open-source computer software library for real-time computer vision and machine learning.
It offers features designed to improve areas, such as image noise removal, contrast-boosting features, and edge detection. The machine learning software library can be incorporated into different use cases to enhance image resolution and data extraction techniques.
Tesseract OCR primarily focuses on text recognition and offers preprocessing features to enhance image quality before OCR. Tesseract’s built-in image binarization and deskewing functionalities improve the clarity of scanned documents and optimize OCR accuracy.
Neural networks and machine learning models are high-level, complex mathematical models used for image data analysis and apply corrective mechanisms to image issues like blur, noise, and color shift.
By training on large datasets, neural networks can intelligently adjust images, optimizing them for accurate OCR and improving the reliability of data extraction processes.
Maintaining high image quality is important for successful data extraction workflows. This involves regular equipment maintenance, like cleaning, calibration checks, firmware updates, and staff training.
Adopting standard scanning practices helps maintain uniformity and consistency in the images acquired. Lay down protocols for scanning documents, such as the appropriate resolution, colors used, and the format in which documents are scanned.
Regulate and control the variability scanning protocols to prevent distortion of image quality and inconsistency in data extraction methods.
Establish inspection points throughout the data extraction workflow to inspect scanned images for clarity, readability, and accuracy.
Training is essential to help the employees provide the best setting and use of scanning and imaging equipment. Establish staff-training programs to explain the procedures and guidelines for handling documents, the proper methods of scanning the documents, and the quality-control measures. The staff should know how to use the scanning equipment properly, fine-tune them if necessary, and resolve potential problems.
Technological upgrades help improve image quality, enhance data extraction activities, and remain relevant. This includes ensuring that the scanning and imaging equipment is up to date in terms of technology due to the regular technological enhancements. The target is to remain up-to-date on new advances in the hardware and the software used to perform scans, as well as the methods involved in the actual processing of the images.
Seek employee feedback about how scanner protocols, quality assurance procedures, and staff education are effective. When embracing feedback and improvement are constant processes, it becomes easier to improve the existing processes and provide consistently high image quality in extracting data.
Poor image quality can impact productivity and operational efficiency. Strategies like manual adjustments, software solutions, optimal scanning settings, and specialized OCR settings overcome these challenges and help address image quality issues in data extraction.
Advanced image processing software enhances image quality to retrieve data from specific fields and present it in a structured format for further analysis and processing.
Docsumo is one of the best data extraction software with over 99% accuracy rate, robust OCR technology, and pre-trained API. It captures and extracts data from various document formats, including scanned images, PDFs, and digital documents, and offers advanced solutions to automate document processing and ensure high-quality data extraction. Customizable workflows allow users to tailor extraction processes to their needs.
Get in touch with Docsumo today to take the next step in upgrading your data extraction processes.

Businesses can improve image quality for better data extraction by implementing best practices such as using high-resolution images, ensuring proper lighting conditions, and minimizing noise and artifacts. Purchasing better scanning equipment and improving image processing would improve the overall image and increase the degrees of accuracy of the information extracted.
Some of the biggest challenges of image processing in data extraction are low-resolution images, bad image brightness/contrast, document physical damages, and image noises/artifacts, which lead to inaccuracy and errors in the extracted data and affect the reliability of data extraction.
Tools like Adobe Photoshop, ABBYY FineReader, OpenCV, Tesseract OCR, neural networks, and machine learning models offer features for enhancing image quality, such as noise reduction, contrast enhancement, and image binarization.


