Suggested
12 Best Document Data Extraction Software in 2025 (Paid & Free)
Extracting critical information from these documents – applications, claims forms, medical records – can be a time-consuming nightmare. Data extraction automates the process, slashing processing times and boosting accuracy.


Data extraction is the process of gathering insights from various documents. It plays a pivotal role in shaping operational strategies and customer experiences. This article highlights its significance, challenges, and best practices in the insurance sector.
Understand the benefits of efficient data extraction, from improved decision-making to cost reduction. Get insights into future trends shaping the industry.
Data extraction plays a crucial role in document management within the insurance industry. Insurers gather data points from various documents, including forms, invoices, contracts, and health reports. This process helps them with accurate risk assessment, claims processing, and insurance premium calculations.
However, manually retrieving information from various documents can be time-consuming and prone to errors. Manual data entry and document processing can slow down claims processing and underwriting, causing delays in policy issuance and claims settlements. Additionally, human errors in data entry, calculations, and documentation pose significant risks.
This is why efficient data extraction is necessary to assess applicant risk. With the correct tools and methods, insurers can work faster and derive more accurate sights, benefiting the company and its customers.
Thus, automation speeds up data processing, reducing the time needed for policy issuance and claims settlements. It enhances customer satisfaction and streamlines claims processing.
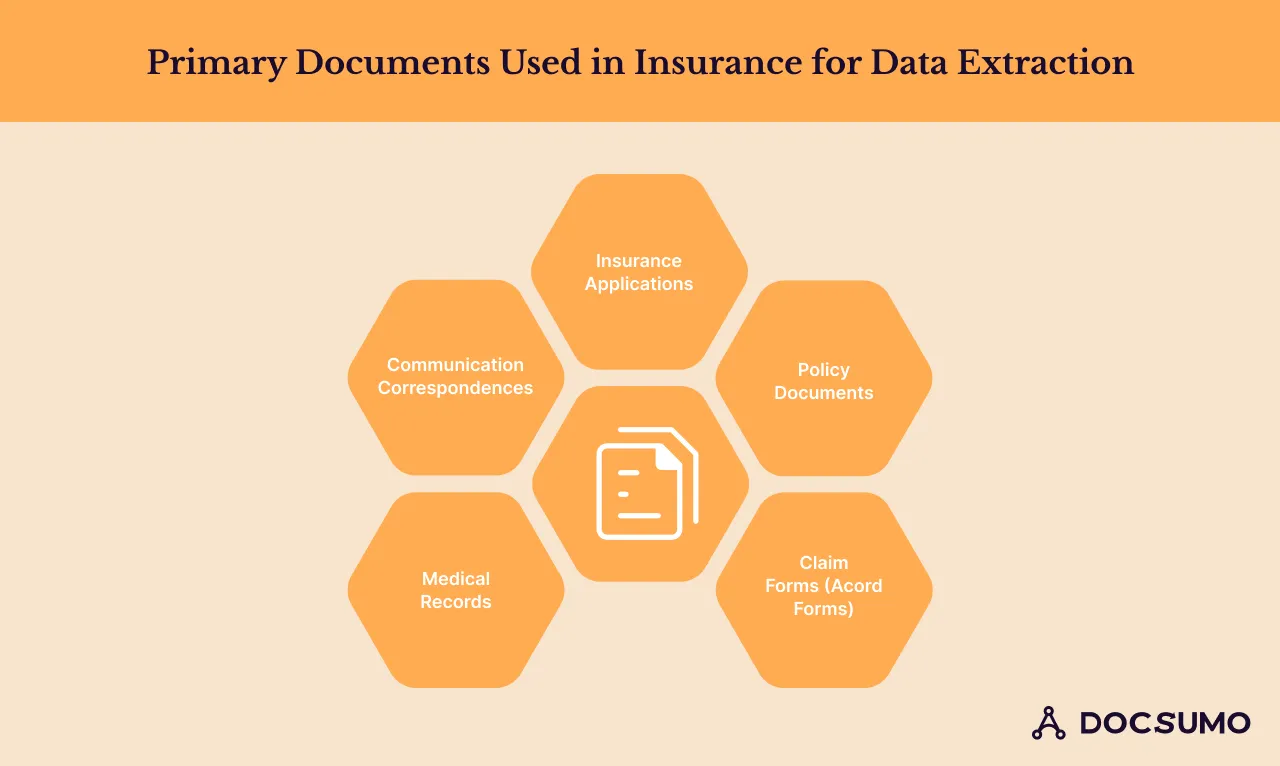
Insurance companies typically extract data from the following documents:
A document containing information, statements, and exhibits to get insurance commitment. An individual completes these forms while seeking insurance coverage. They gather necessary information for insurers to evaluate risks and determine appropriate coverage.
These written contracts establish the terms and conditions of insurance coverage. They detail what is covered, excluded, and the procedures for claims processing. Policyholders rely on these documents to understand their rights and responsibilities.
Standardized forms are utilized for reporting insurance claims. They capture essential details of the incident or loss. Timely and accurately completing claim forms is crucial for initiating the claims process.
Documents containing an individual's health-related information, including diagnoses, treatments, medications, and test results. They play a vital role in providing evidence of medical history for underwriting and claims assessment.
Written exchanges between the policyholder and the insurance provider, such as emails, letters, or messages. They serve as a record of communication about policy updates, claim status, or general inquiries.
Examples include driver's licenses, passports, birth certificates, and social security cards. Insurers may request these documents to prevent identity theft or fraud.
Here are some common types of challenges faced by insurance companies in data extraction:
Insurance companies deal with a vast amount of data from various sources, including both structured and unstructured data. Extracting meaningful insights from such a diverse data landscape poses challenges to processing speed, scalability, and the ability to handle large volumes of data efficiently.
Accurate data extraction is vital in insurance to prevent misinterpretation of policies, claim processing errors, and regulatory violations. Additionally, safeguarding customer data during extraction is essential to maintain trust and security.
Insurance companies often use multiple systems and platforms for their operations. But, integrating data extraction solutions with existing systems and workflows can be challenging. They demand compatibility and interoperability across different platforms.
As insurance businesses grow and evolve, the demand for data extraction capabilities increases. Scalability becomes a challenge as existing extraction methods may need help to handle larger document volumes. Ensuring that extraction solutions can scale to meet growing demands is crucial for operational efficiency.
Implementing and maintaining robust data extraction systems can be costly. This is especially true for smaller insurance companies or those operating on tight budgets. Balancing the cost of implementing extraction technologies with the benefits of improved efficiency is a common challenge.
Ensuring the quality and consistency of extracted data can be challenging due to variations in document formats, language, and handwriting. More accurate and consistent data can lead to errors in decision-making and operational inefficiencies. Implementing reliable data validation methods can help address these challenges.
The insurance industry requires strict adherence to data privacy laws and regulatory requirements. Ensuring data extraction processes follow these regulations while maintaining efficiency can be complex. The complexity is further increased by the need to navigate evolving regulatory landscapes.
Many insurance companies still rely on legacy systems and manual processes for data extraction. These systems often need to be more efficient and error-prone. Transitioning from outdated systems to automated extraction methods presents cost, time, and training challenges.
Today's customers expect personalized experiences. Insurers must navigate complex data landscapes to extract meaningful insights and deliver tailored products and services.
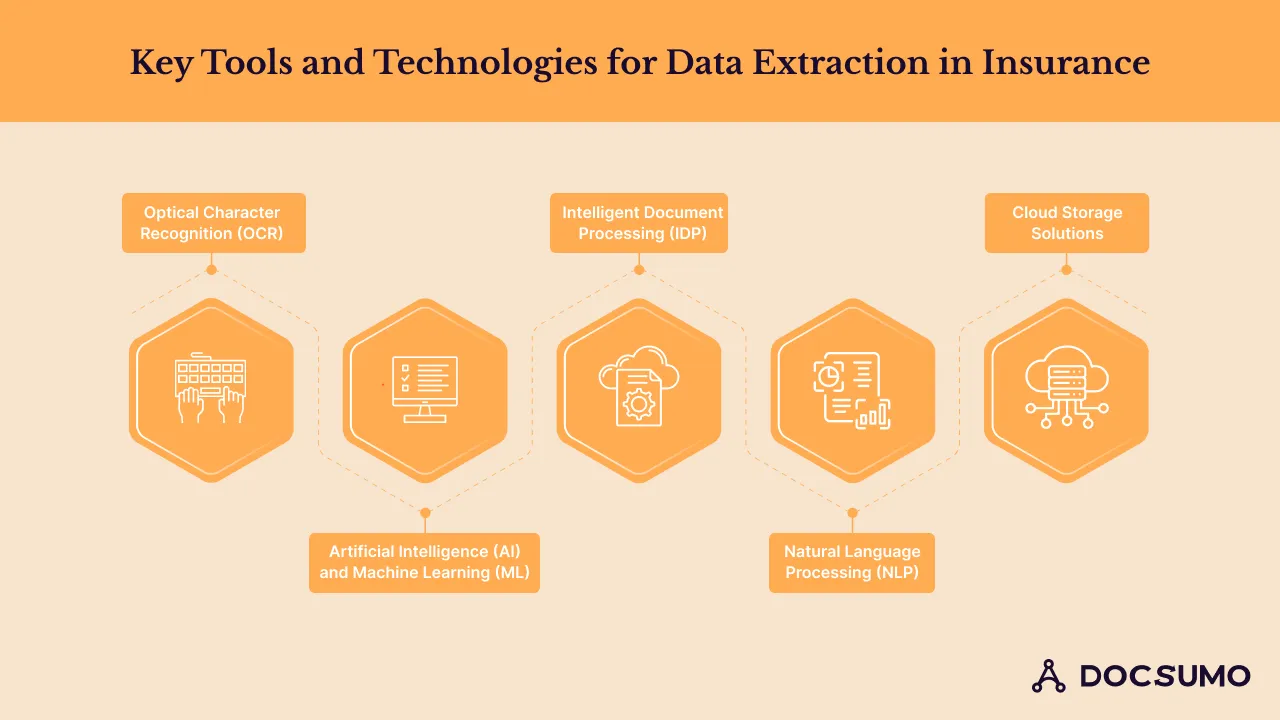
Optical character recognition (OCR) technology converts scanned documents, images, or PDFs into machine-readable text, allowing for automated data extraction from various sources.
AI and ML algorithms play a vital role in automating data extraction processes by learning from patterns and improving accuracy over time. In insurance, these technologies are utilized for data classification, entity recognition, and information extraction.
NLP enables computers to understand and interpret human language, facilitating the extraction of relevant information from unstructured text data such as insurance policies, claims forms, and customer communications.
Intelligent Document Processing platforms combine OCR, AI, and ML technologies to extract data from structured and unstructured documents, automate document classification, and streamline data entry processes.
Cloud storage solutions provide scalable and secure storage for insurance documents and extracted data, enabling easy access, collaboration, and integration with other systems. Leading cloud storage platforms utilized by insurance companies include:
.png)
Take the following steps to ensure effective data extraction processes:
Define specific data extraction objectives and ensure they align with broader organizational goals. These can include enhancing underwriting accuracy, improving claims processing efficiency, or optimizing customer service.
Data quality is paramount in the insurance industry. Only accurate or complete data can lead to costly errors. Implement quality checks at every stage of the extraction process to ensure that the data is accurate and reliable.
Insurance regulations, customer preferences, and market dynamics evolve. Always update your data extraction systems and rules to adapt to these changes, such as updating extraction algorithms, adding new data sources, and refining data validation processes.
Insurance companies deal with sensitive customer information, thus making data security a top priority. They must ensure robust security measures to protect data from unauthorized access, breaches, and cyber-attacks. This includes encryption, access controls, regular security audits, and compliance with data protection regulations such as GDPR or CCPA.
Train staff in extraction tools, data validation, and security protocols to enhance competency and avoid errors. Effective training programs are key to achieving these goals.
After extraction, integrate the data into existing systems. Integration helps with real-time data access and improves overall operational efficiency. While doing so, ensure compatibility with existing data formats, databases, and applications.
Embrace automation to make data extraction smoother and faster. Automated tools cut down on manual work, errors, and processing time. Platforms like intelligent document processing help with automation. They extract data from various documents and formats, further enhancing insurance workflows.
Establish and monitor KPIs to identify areas for improvement and optimize extraction workflows. This ensures that data extraction aligns with business goals and offers tangible value.
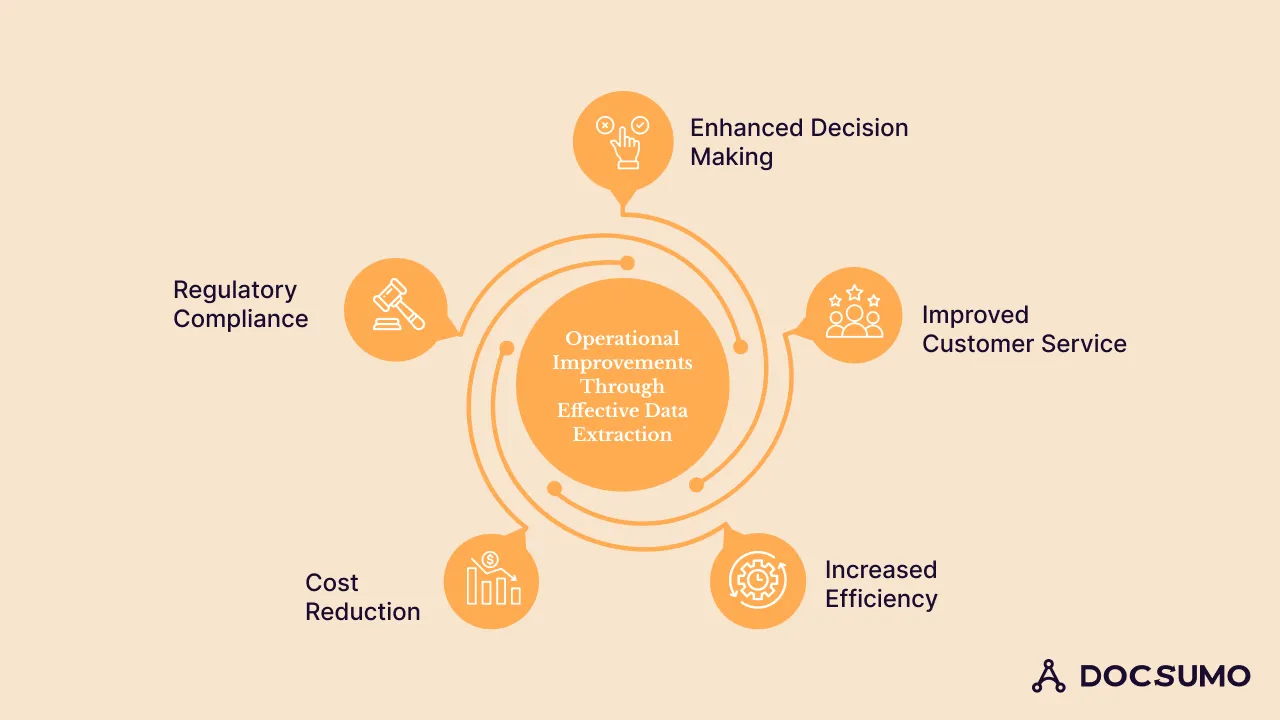
Let's dive into how improving data extraction can make a big difference in how insurance companies serve their customers.
Implementing efficient data extraction processes allows organizations to gather relevant information faster. With timely access to reliable data, decision-makers can analyze trends, identify patterns, and better anticipate customer needs. It ultimately leads to better outcomes and competitive advantages.
For instance, a real estate firm enhanced its data capture accuracy and achieved an STP rate of 95% with the help of an intelligent data extraction software. They do not even have to look at risk assessment documents 95 out of 100 times, and the extracted data is directly pushed into the database.
Similarly, another organization processes thousands of ACORD forms a day automatically while being able to get accurate analytics from over 100 data points.
Streamlining data extraction processes benefits customer service by enabling faster response times and more personalized interactions. This proactive approach enhances overall customer satisfaction, fosters loyalty, and strengthens the brand's reputation. Additionally, access to comprehensive customer information facilitates proactive communication and anticipates future needs.
Optimizing data extraction methods eliminates time-consuming tasks associated with gathering and processing information. By leveraging automation, organizations can streamline workflows. Employees can focus on value-added activities rather than repetitive data entry or retrieval tasks.
Efficient data extraction processes lead to significant cost savings. They also lead to streamlined workflows that result in shorter processing times. Organizations can eliminate redundancies and maximize the return on investment (ROI) in data extraction tools and systems.
Accurate and timely data extraction is vital for regulatory compliance. It also helps organizations maintain audit trails and track data lineage, reducing the risk of penalties.
To conclude, efficient data extraction is pivotal in insurance for accurate risk assessment, streamlined claims processing, and enhanced customer service. Manual methods are prone to errors and inefficiencies, while automation offers speed and accuracy. It ultimately benefits both insurers and policyholders.
Embracing advanced tools and practices is crucial for staying competitive in the industry. If you are looking for a solution to enhance your data extraction process.
Docsumo is an intelligent document processing solution that leverages AI and ML technologies to streamline data extraction, enhance accuracy, and ensure compliance. Its robust features cater perfectly to the complex needs of insurance operations.
Want to learn how Docsumo can revolutionize your data extraction in insurance?


Insurance companies can begin implementing advanced data extraction technologies by assessing their specific needs and challenges. They should research and select a reliable data extraction solution that aligns with their goals and requirements.
Common challenges in data extraction for insurance include handling diverse data volumes and ensuring accuracy, security, and regulatory compliance. Integrating solutions with existing systems and managing scalability, cost, and data quality are significant hurdles.
Future trends in data extraction for insurance include further advancements in AI and ML technologies. Cloud-based solutions will be more widely adopted, and real-time data processing and analysis will be emphasized.


