Oops! Something went wrong while submitting the form.
A PDF file can have text stored as a content stream or it could simply be a scanned image converted to the PDF format. Data extraction from the first kind of PDF document is relatively easier but for the second kind of pdf files and images, accurate data extraction remains a challenge. Extracting data from scanned/non-scanned pdf files and images have been made possible by Zonal OCR.
We'll discuss what Zonal OCR is and how it works in this article.
So, let's jump right into it:-
What is Zonal OCR?
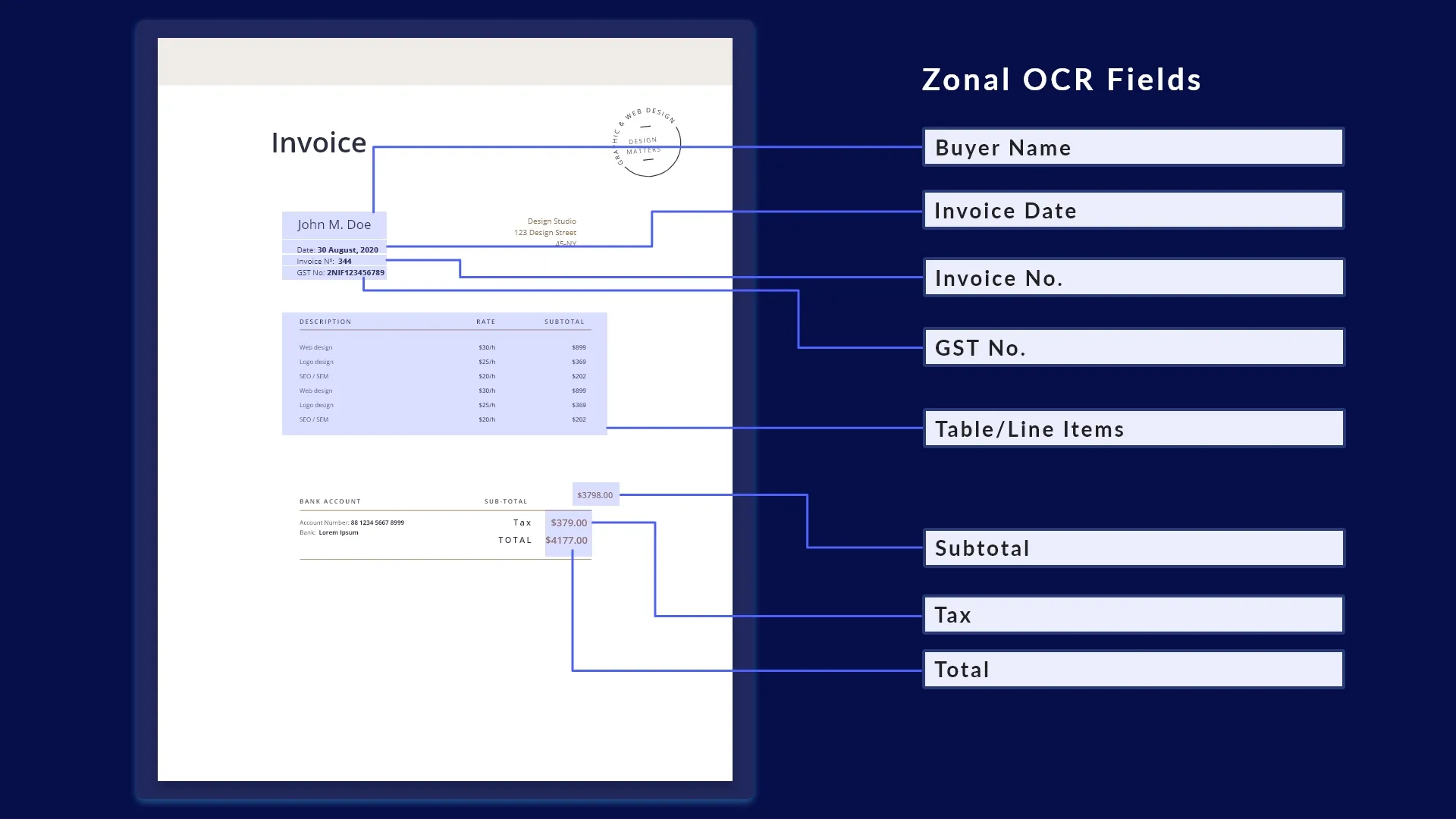
Zonal OCR can be considered the second generation of Optical Character Recognition (OCR) technology. Zonal OCR or template OCR can identify text located in specific areas(zones) on a document or an image. It is used when specific parts of a document need to be extracted zonally.
How Zonal OCR is different from Traditional OCR
Traditional OCR extracts data from all fields in documents without discriminating or being specific about the values. Tables, columns, graphical elements, scanned images, etc., all data fields are read when processing paper documents with these solutions. Zonal OCR focuses on extracting specific areas of documents and goes beyond traditional optical character recognition by distinguishing the fields it extracts from the rest. The software algorithm doesn’t just convert scanned images into text, it understands the structure and hierarchy of your documents. And the extracted data is stored in structured databases, with custom data extractions being possible for different document layouts. Modern OCR uses pre-defined templates for data extraction but Zonal OCR uses intelligent analysis for recognizing characters and various data fields.
How Zonal OCR works
Zonal OCR can be configured into document scanning software to extract specific zones or data fields documents. The OCR software searches for index numbers on pages and creates zones from where the data is extracted. Dynamic forms of Zonal OCR can intelligently reorganize documents and let users use regular expressions to define complex search parameters for customizing data extraction.
Regular expressions are used commonly in Python and Perl for various document parsing applications. Users can set up scanning templates for bulk processing documents by defining zones for different documents and full zonal OCR systems can also be used for extracting meaningful phrases, words, and line items from reports. Some platforms feature a zone designer which is embedded with the document extraction interface and these do not require installing any third-party software for using them. The technology is mainly used for automating data extraction from documents and companies can extract data for sharing it with other staff members in secure and cost-effective ways.
The way Zonal OCR works is that it creates zones in documents and sets margins for full pages. All the data is extracted from within these boundaries and anything outside is left out. Any characters that are partially entered in data fields cannot be read and the program displays these areas as error messages. Creating “smart zones,” using regular expressions, can enable users to optimize data extraction, achieve greater accuracy, and allow users to set formatting rules for advanced document processing post data extraction.
Applications of Zonal OCR
If you have a set of data in PDF format that needs to be extracted in key-value pairs or table format, Zonal OCR is the answer. It can trace different sections in a document and extract text.
Let’s see how Zonal OCR works for invoices.
An invoice contains various fields, such as:-
Name
Date of transaction
Invoice Number
Products purchased
Costs, etc., all at different locations.
A well trained Zonal OCR model can identify all of this data separately, extract, and store in a structured database.
Other use-cases of Zonal OCR technology in different industries:-
Zonal OCR lets users capture relevant data from documents, forms, PDFs, and e-documents and is used for automating document management workflows in business processes. It eliminates the need for manual human intervention and reviews via intelligent analysis and helps businesses shift to paperless document processing.
It makes data fields easily retrievable, searchable, and editable by storing the extracted data in structured databases. Zonal OCR can be used to organize and sort through unstructured documents. It scans metadata details from documents, uses it to arrange files, and facilitates a “touchless form,” of document processing.
Helps users save countless hours of time by eliminating manual data entry. Zonal OCR can extract data from a variety of documents and convert the extracted information into different file formats for efficient document storage. Businesses can save up to 20% of their revenue since no re-corrections are involved via automated data extraction. Zonal OCR is reliable, scalable, and accurate and adapts to various enterprise data processing requirements.
Zonal OCR improves organizational performance and productivity since it enables end-to-end automation for core business processes. It avoids data redundancy, duplicate entries, missing values, and ensures that data extracted is kept up-to-date. Advanced Zonal OCR workflows can extract data based on custom layouts, split documents into different parts, categorize line items, and perform feature-based data extractions according to user requirements. The technology can be used for processing handwritten notes, cursive texts, and texts from scanned documents as well, including giving users the ability to ignore graphical elements during the extraction process for better accuracy.
Cons of Zonal OCR
Outdated Zonal OCR software solutions cannot extract sequential data items in forms, paper-based documents, and pre-defined fields. For example, one of the challenges of this technology is extracting sequential product numbers from same invoices/receipts.
Sometimes Zonal OCR cannot extract data from semi-structured documents where the fields that need to be extracted are located in different positions of the document. Zonal OCR also face the problem of being unable to extract data such as multi-line postal addresses and compound data fields
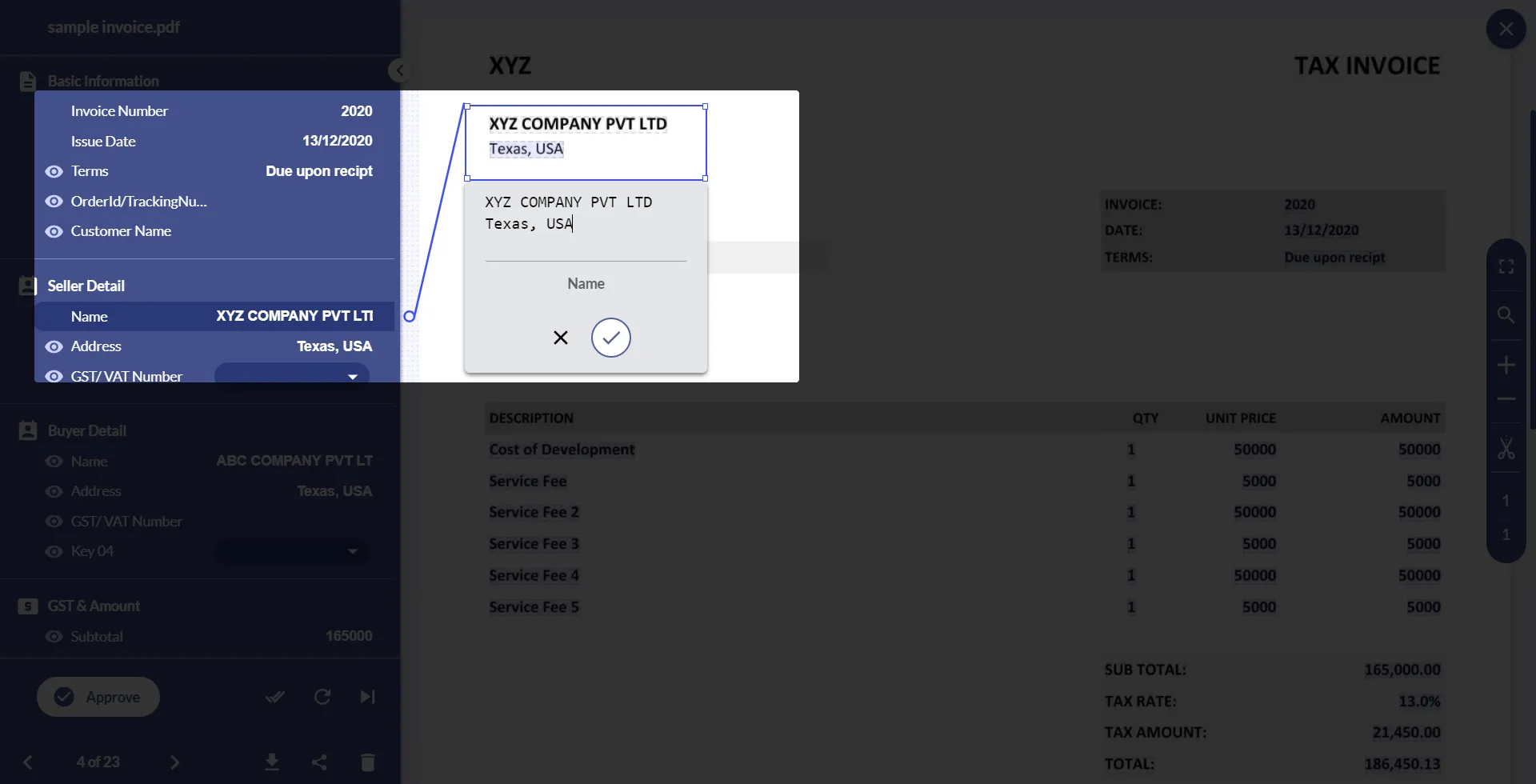
Docsumo and Zonal OCR
Docsumo uses advanced AI models to extract data according to different document layouts. Docsumo creates APIs for customizing data extraction and starts with document annotation where users can define ‘zones,’ and annotate fields in the initial document.
Users can create key-value pairs to define fields for data annotation and let the API know which areas they are interested in. The API carefully scans through these fields and extracts all line items associated with them. Docsumo is also capable of reading texts from scanned images, PDF documents, logos, graphics, barcodes, and other visual elements present in documents.
Once the API does key-value pair extraction, it requests the user to review the changes. If the user is happy with them, he/she approves and the API saves the workflow for further document processing.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.


.webp)
