
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.
The general approach to improving the accuracy of deep learning models is to increase the training data. This approach has been highly rewarding in many domains, which are predominantly rich in the capacity to produce labeled data.
The general gradient-based optimization in high-capacity models, if trained from scratch, requires many parameter-updating steps over a large number of labeled examples to perform well (Snell et al., 2017).
In the small data regime, where we want to learn from a very small number of labeled examples, this kind of optimization fails. In contrast, humans can quickly learn to solve a new problem just from a few examples. For example, given a few images of an unknown person, it is easy to recognize them from a large number of images. This is not only due to the human mind’s computational power but also to its ability to synthesize and learn new information from previously learned information. For example, if a person has a skill for riding a bicycle, that skill can prove helpful when learning to ride a motorcycle.
Recent years have seen a rise in research attempting to bridge this gap between human-like learning and machine learning, which has given birth to this new sub-field of machine learning known as Few-Shot Learning (FSL), i.e., the ability of machine learning models to generalize from a few training examples.
When there is only one example to learn from, FSL is also referred to as One-Shot learning. The motivation for FSL lies in the fact that models excelling at this task would have many useful applications.
There are not 1, not 2, but 4 different variants of few shot learning. They are:-
i) Meta-learning
ii) Using latent embedding
iii) Transfer learning
iv) Prompting
In this article, I am going to touch upon all of them. The goal of this article will be to provide a theoretical understanding of these approaches. Each of these deserves a separate technical tutorial. In my upcoming articles, I will discuss each of these variants one by one, providing implementation tutorials for each.
Much of the recent progress in FSL has come through meta-learning. Therefore, we first divide the approaches to FSL into two categories:
Meta-learning, or 'learning to learn,' forms the foundational technique employed by most few-shot learning algorithms.
Inspired by human development theory, meta-learning—a subset of machine learning—emphasizes learning priors from past experiences that can facilitate efficient downstream learning of new tasks.
Consider, for instance, a simple learner and a meta-learner. While a simple learner learns a singular classification task, a meta-learner comprehends learning to solve a classification task by exposing itself to multiple similar classification tasks. Consequently, when faced with a similar but new task, the meta-learner can solve it more quickly and effectively than a simple learner, that lacks prior experience in tackling the task.
A typical meta-learning procedure involves learning on two levels: within tasks and across tasks. Initially, rapid learning occurs within a specific task, such as accurately classifying a particular dataset. This learning is then steered by knowledge gained more gradually across tasks, capturing the variation in task structure across target domains. This two-level learning approach allows meta-learning to quickly adapt to new tasks, highlighting its effectiveness in few-shot learning scenarios.
Conventionally, a task-specific model is trained by iterating through task-specific labeled examples. For instance, in text classification problems, an input sentence is treated as a training example. However, the meta-learning framework flips this approach, treating tasks themselves as training examples. To solve a new task, we gather a multitude of tasks, each treated as a training example, and train a model to adapt to these tasks. This model is then expected to perform well on the new task.
In typical text classification tasks, we assume that the training sentences and test sentences come from the same distribution. Meta-learning mirrors this assumption, positing that training tasks and new tasks originate from the same task distribution, denoted as p(T). During meta-training, a task T_i is sampled from p(T). The model is trained with K samples and then tested on a test set from T_i. The test error on the sampled task T_i is considered the training error of the meta-learning process at the current (i-th) iteration.
Once meta-training is completed, the performance of the model on a new task, also sampled from p(T), is measured after learning from K samples.
To mirror the conditions of the new task, which only has K-labeled examples and a large set of unlabeled test instances, each training task also maintains only K-labeled examples during training. This ensures that the training examples (or training tasks in this context) share the same distribution as the test example (or the new task). These K-labeled examples are commonly referred to as a "support set."
Now, let’s talk about the popular meta-learning methods for NLP and how they fit into NLP tasks
In typical deep learning, gradient descent is widely used to solve:

Gradient descent starts with a set of initial parameters θo, and then the parameters θ are updated iteratively according to the directions of the gradient. There are a series of meta-learning approaches targeted at learning the initial parameters θo.
In these learn-to-init approaches, the meta parameters φ to be learned are the initial parameters θo for gradient descent, or φ = θo. MAML (Finn et al., 2017) and its first-order approximation, FOMAML (Finn et al., 2017), Reptile (Nichol et al., 2018), etc., are the representative approaches of learn-to-init.
The key idea in MAML, or Model-Agnostic Meta-Learning is to achieve good initialization parameters θo such that new tasks can be optimized quickly from θo to θ* through one or more gradient descent steps computed over a small amount of data. These initial parameters θo are meta-learned over a distribution of tasks p(T). Individual tasks use the model parameters θo as initialization to arrive at optimal parameters θ* for the task at hand.
The "Learning to Compare" methods are widely used in various Natural Language Processing (NLP) tasks, which include, but are not limited to, text classification, sequence labeling, semantic relation classification, knowledge completion, and speech recognition. These methods are predominantly based on matching networks, prototypical networks, and relation networks, and they primarily extend these architectures in two fundamental ways:
The first aspect relates to the process of embedding text input into a vector space. This could be done with or without the inclusion of context information. The goal is to transform the raw text into a numerical format (or a vector space) that a machine-learning model can understand and process. This transformation is usually executed through techniques like word embeddings or transformer models.
The second aspect involves computing the distance, similarity, or relation between two inputs within this vector space. This step is crucial as it helps the model understand and quantify the level of similarity or difference between pairs of text inputs, which contributes to tasks like text classification or semantic relation classification.
These questions have been at the heart of computational linguistics research for many years, which is why "Learning to Compare" methods are considered key among other meta-learning methods in the context of NLP, despite their conceptual simplicity. It's important to note that these methods have mainly been applied to classification tasks.
Neural network architecture search (NAS) is another common meta-learning technique applied to NLP, including language modeling (WikiText103, PTB), NER (CoNLL-2003), TC (GLUE), and MT (WMT’14). These techniques are often trained/evaluated with a single, matched dataset, which is different from other meta-learning approaches.
Moreover, in contrast to conventional NAS methods that focus on learning the topology in an individual recurrent or convolutional cell, NAS methods must be redesigned to make the search space suitable for NLP problems, where contextual information often plays an important role.
To demonstrate the efficacy of NAS, I have summarized the performance of several state-of-the-art NAS approaches on GLUE benchmarks (Wang et al., 2019a) in figure below.
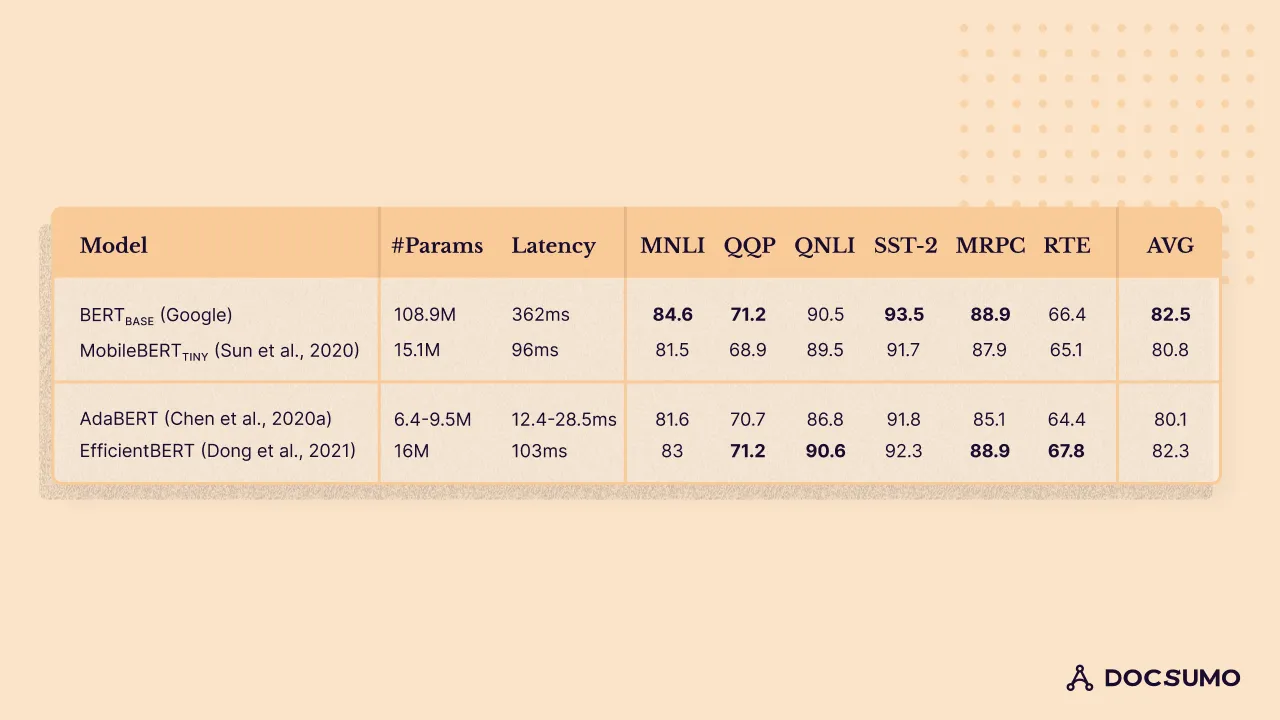
These approaches are applied to BERT to discover architectures with smaller sizes, faster inference speed, and better model accuracy. For comparison, performance from original and manually compressed BERT models is also presented. The results show that the BERT architecture improved by NAS yields performance competitive to BERT (figure 1, 82.3 from EfficientBERT vs. 82.5 from BERT) and is 6.9x smaller and 4.4x faster. The search architecture also outperforms manually designed, parameter- and inference-efficient models (MobileBERTTINY) at similar size and speed. These results suggest the efficacy of NAS in discovering more efficient network architectures. As NLP researchers continue to design even larger PLMs while the need for deployment of edge devices grows, we expect there will be increasing investment in innovative NAS techniques to make PLM networks more compact and accelerate inference.
Multi-linguality, multi-task, and multi-label see many impacts on NLP problems due to the diversity of human languages. To learn models with balanced performance attributes (e.g., languages, tasks, labels), a common approach is to weigh the training examples for data selection to learn models with balanced performance over the attributes, and it is a natural assumption that meta-learning techniques derive more generalizable weighting than manually tuned hyperparameters.
We can do this by adding another gradient update step and wrapping the conventional classifier update for training meta-parameters that control the weight when aggregating losses from different labels to update the classifier’s parameters. In addition to gradient updates, meta-learned weights are applied directly to training examples for data selection to address the issue of noise labeling.
Additionally, in research on pre-training and transfer learning, there is a trend of leveraging datasets in multiple languages, domains, or tasks to jointly pre-train models to learn transferable knowledge. A meta-learned data selector can also help in this scenario by choosing examples that benefit model training and transferability. For instance, Wang et al. (2020b) investigate the common challenges of imbalanced training examples across languages in multilingual MT, which is conventionally addressed by tuning hyperparameters manually to up-sample languages with fewer resources. The authors propose Differentiable Data Selection (DDS) to parameterize the sampling strategies. DDS is trained with episodes and REINFORCE algorithm to optimize parameters of sampler and MT models in an alternating way for the MT models to converge with better performance across languages
Here we have summarized the 4 main types of meta-learning approaches for NLP. There are many other variations of the few-shot learning problem and the hybrid meta-learning-based approach towards them.
In this section, we discuss strategies other than meta-learning that can aid learning in a limited data regime.
Transfer learning is a method that enhances learning for a new task by transferring knowledge from a related task that has already been learned. In a few-shot learning scenario where the available data is too sparse to train a deep network from scratch, the application of transfer learning by leveraging knowledge from a different network can be a feasible approach. Specifically for a classification task, this transfer of knowledge can be accomplished by initially pretraining a deep network with copious amounts of training data on base classes (that are already observed), and then fine-tuning this pre-trained model on new few-shot classes (that are yet to be seen).
Recently, by leveraging the self-supervised technique, we have been able to train models that can learn high-quality, high-dimensional representations of natural language. This has decreased our need for huge amounts of labeled data. These models need to be fine-tuned in a supervised fashion for the downstream use case (sentiment analysis, simple document classification, information extraction, etc.). Finetuning an already pre-trained model significantly cuts our labeled data needs. It also drastically reduces the turnaround time for building machine learning applications, making it a low-cost solution.
An embedding method is used to generate a document representation and, separately, representations for each of the possible class labels. A document is then assigned the label that lies closest to it in the text embedding space. Note that we do not necessarily need the documents to be labeled a priori (in contrast to supervised learning, in which the model learns relationships explicitly from labeled examples).
The underlying concept this method relies on is that humans are innately capable of categorizing documents into predefined categories without any specific training. This innate ability stems from our understanding of the semantic meanings associated with category labels. For instance, consider the task of categorizing news articles. We can instinctively determine whether an article fits under the 'Science and Technology' or 'Business' category (or perhaps both!) given our understanding of the words "Science," "Technology," and "Business." This understanding of the intrinsic meaning of words, particularly class labels, is the key piece of information leveraged for classification.
By harnessing the power of these semantic meanings within the embeddings, the model can categorize documents effectively with few examples, demonstrating the essence of few-shot learning in NLP.

To appreciate how text embeddings work, let's consider a practical example. Say we have a collection of news articles that we want to classify into one of these categories: world news, business, science, technology, or sports. We have, at our disposal, an "Embedding Model" that is capable of assigning numeric vectors to given text segments.
We employ this embedding model to transform our news article and the associated labels into a latent space - a condensed representation of the data where similar data points cluster together.
Take this news article, for instance: “Breaking baseball barriers: Marlins announce first female GM in MLB history.” We feed the text of this article and the labels through our embedding model. This process is akin to, but not the same as, what is illustrated below.
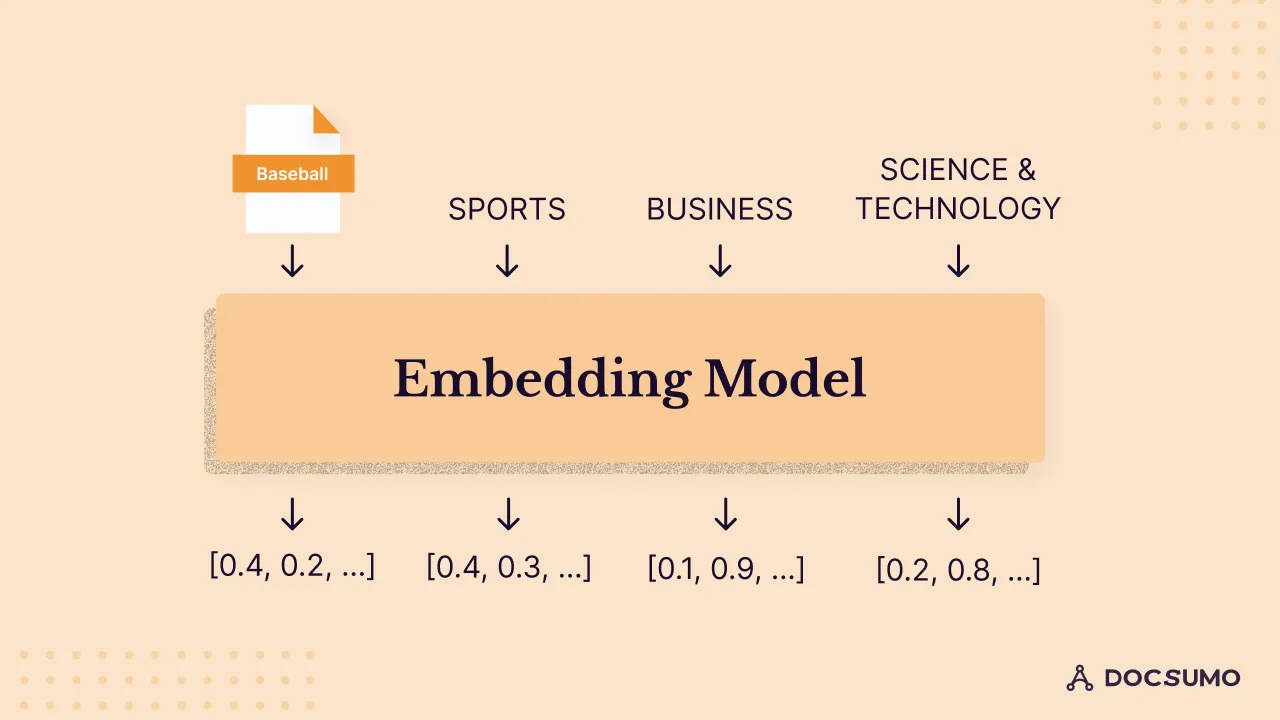
A news article and each of the labels are passed through the Embedding Model to generate vector representations for each text segment.
This produces embedding vectors that we can plot in our latent space:
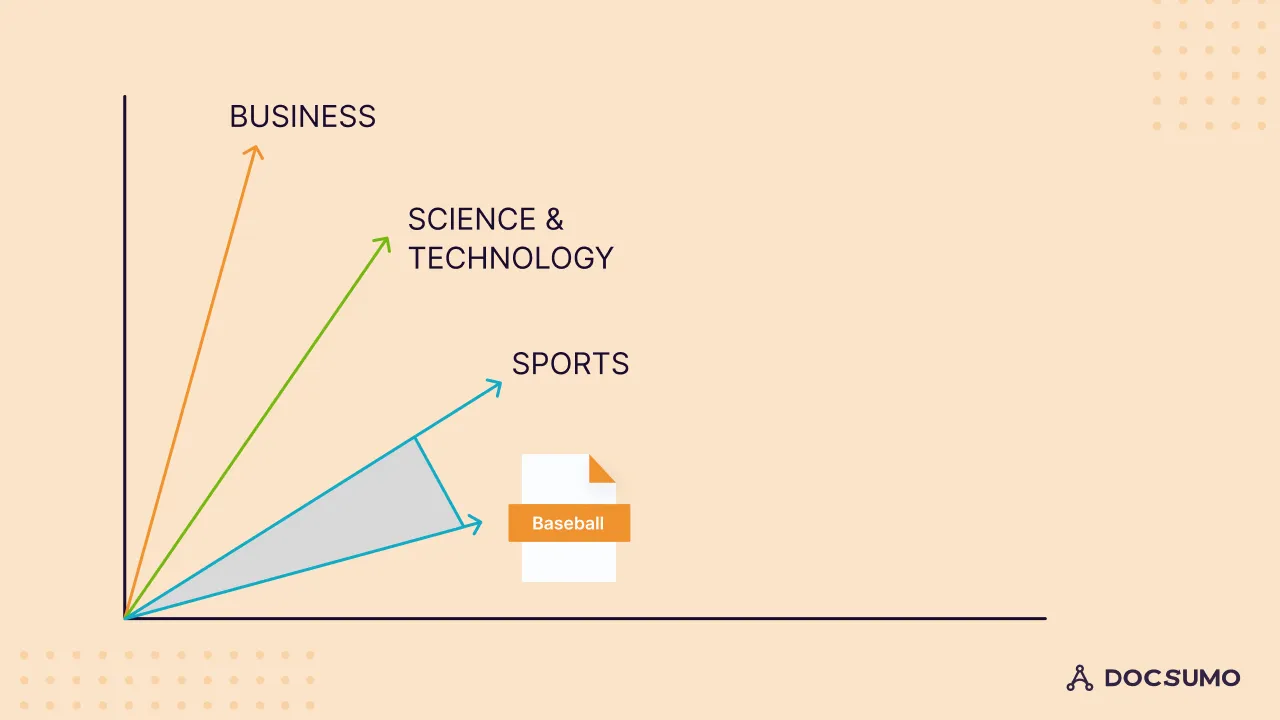
Each vector - one for the news article and one for each label - is represented in this latent space. The vector corresponding to the news article is closest to the vector representing "Sports," so "Sports" is assigned as the label.
To pinpoint the label that is closest to our news article in latent space, we employ a similarity metric, like cosine similarity, which indicates the degree of similarity between text segments. In our example, the article shares the highest similarity with the "Sports" label, so we assign "Sports" as the document category. This assignment is based on the semantic similarity between "Baseball" (the topic of our news article) and "Sports."
Crucially, this classification doesn't rely on training data. Instead, it leverages intrinsic semantic similarities between words and sentences, demonstrating the power of few-shot learning in NLP.
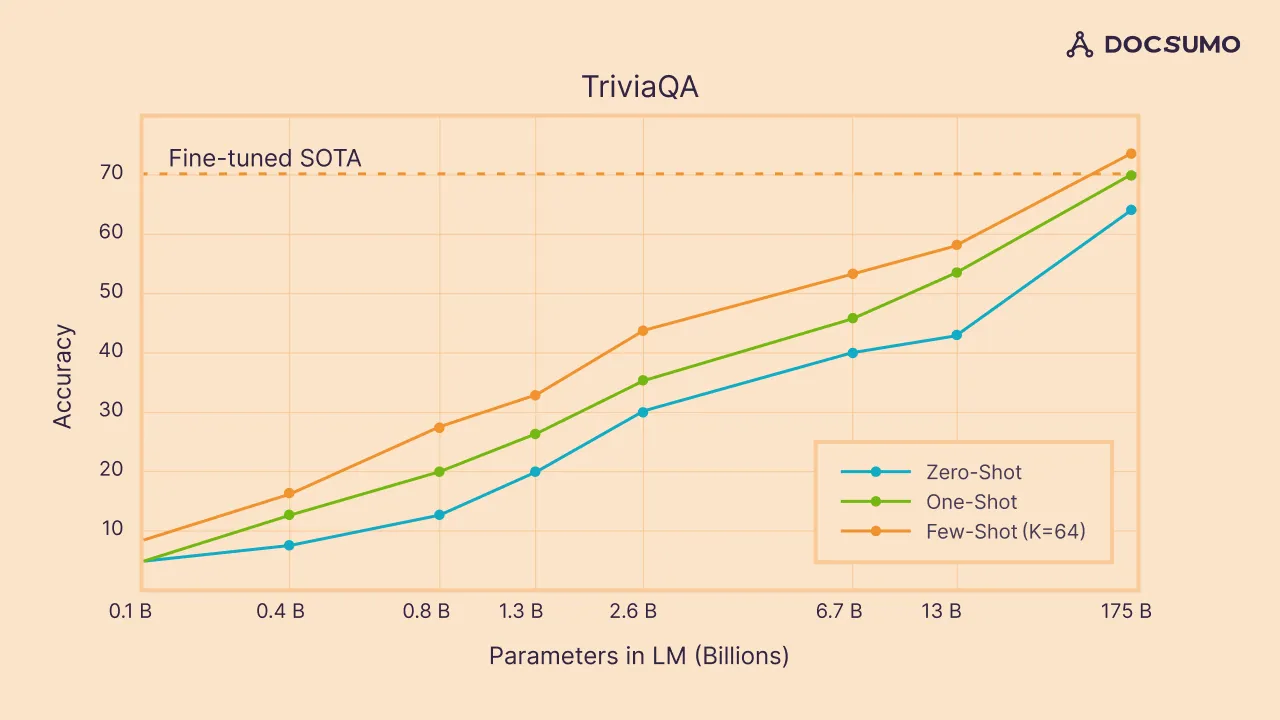
In the realm of few-shot learning, one of the prominent methods is prompting. This technique is particularly powerful when used with large language models, which are, in fact, few-shot learners. These models, during their pre-training phase, absorb a plethora of tasks implicitly from extensive text datasets, thereby learning to perform a wide array of tasks.
The first stage of their evolution involves pretraining in a self-supervised autoregressive manner, where the goal is to predict the next token. Subsequently, through a process known as instruction tuning, these models are fine-tuned to answer user queries. Some models undergo further optimization using reinforcement learning strategies to enhance their helpfulness, correctness, and harmlessness.
The culmination of these processes equips the model with the ability to generalize. In other words, these models gain the capability to understand and perform tasks that are related but previously unseen, with just a handful of examples to learn from.
Few-shot NLP example consists of three main components:
Recent LLMs like Gpt-3.5, LLama2, BART, and others can even work without any examples. This is called zero-shot learning, where you don’t need to provide examples.
Let's take a moment to encapsulate what we've discovered throughout this article.
Historically, the primary focus of early few-shot learning research was computer vision applications, predominantly image classification. This was largely due to the ease of obtaining visual information and its extensive exploration within the machine learning paradigm. However, as we've unveiled in this article, the scope of few-shot learning extends significantly into the realm of Natural Language Processing (NLP).
NLP as a field is undergoing rapid evolution, which has propelled the swift progression of applications based on few-shot learning techniques. An area that hasn't seen as much light on NLP, but holds enormous potential, is meta-learning. I firmly believe that meta-learning could be pivotal across various use cases.
To delve deeper into these fascinating areas, I plan to author separate comprehensive tutorials on meta-learning and non-meta-learning Few-Shot Learning within NLP. These detailed articles will guide you through the technical implementation of a myriad of use cases. I look forward to continuing this exploration in the upcoming pieces. Until then, keep questioning and keep learning.
Save 100+ hours a month by automating all your low-impact tasks so that your team can prioritize faster and accurate business decisions, every time.
Get Your Free Trial Today

.webp)
.webp)
.webp)