Oops! Something went wrong while submitting the form.
Docsumo is an intelligent document processing solution that excels at extracting information and structuring it from unstructured sources. Powered by AI, it is able to turn data from invoices, receipts, payrolls, Acord forms, and various documents into an electronic format for automated processing. If you’re new to Docsumo or if it’s your first time scanning and reading information from physical documents, this handy guide will walk you through the process.
How to train a Document (Step-by-step)
Training your document using Docsumo entails two phases – creating a new document type and using it.
An API can be used to process multiple documents of the same category. For example, driver’s license, PAN Cards, and Aadhar are classified under Indian KYC. Likewise, Insurance Compliance Documents comprise of Acord 130, Acord 25, and other types of Acord forms.
Here is an overview on how to create, train and use Docsumo APIs to read and process your documents.
Create and Train Your API
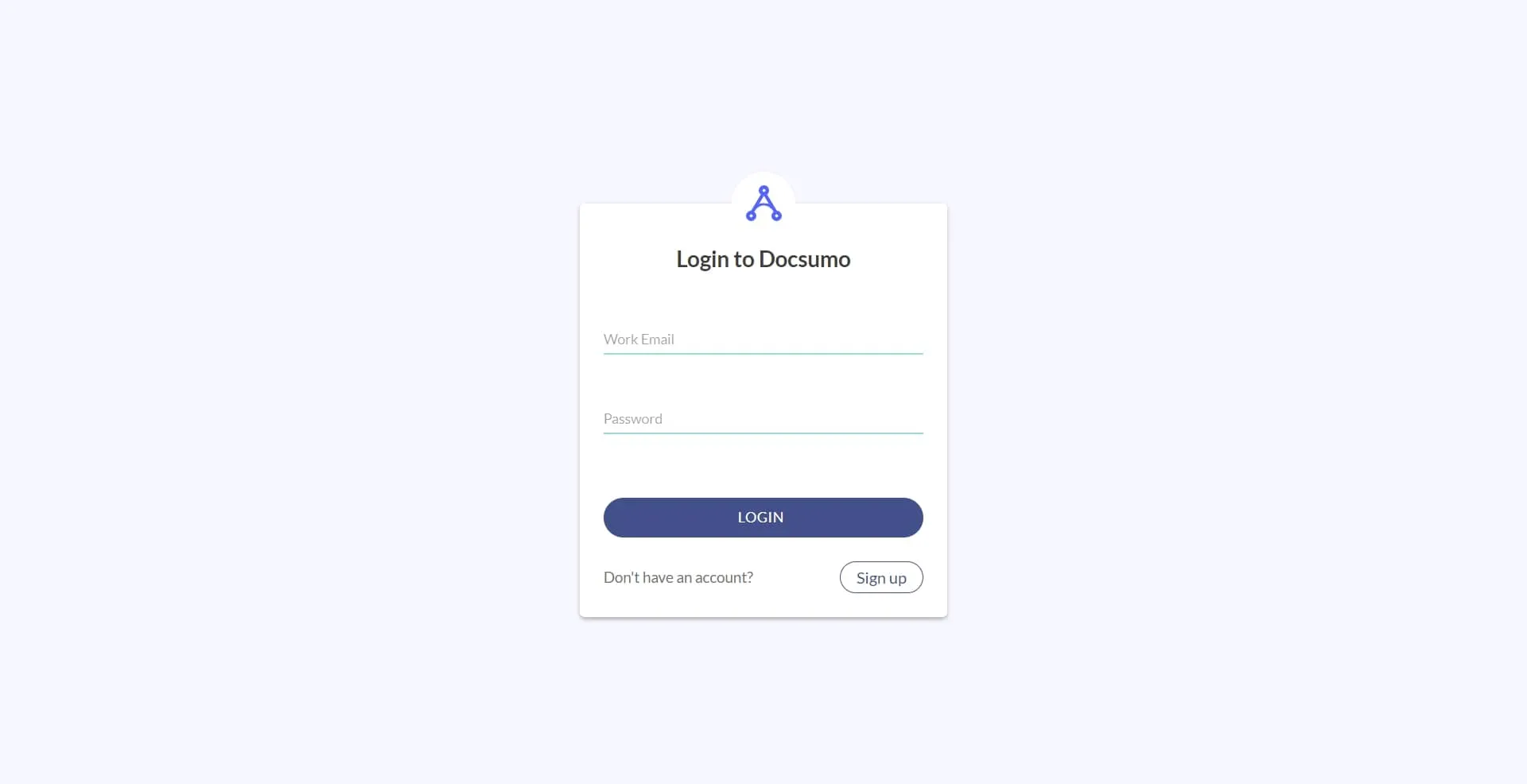
1. Before you get acquainted with the Docsumo user interface, make sure you sign up for an account on the platform and log in. To access the Docsumo dashboard, visit app.docsumo.com and enter your email and password.
2. The basic workflow is that you use a pre-trained API to scan and read multiple documents. Pre-trained APIs on the platform use machine learning algorithms to intelligently read documents and extract key value pairs. However, you can always train the model for a new document type.
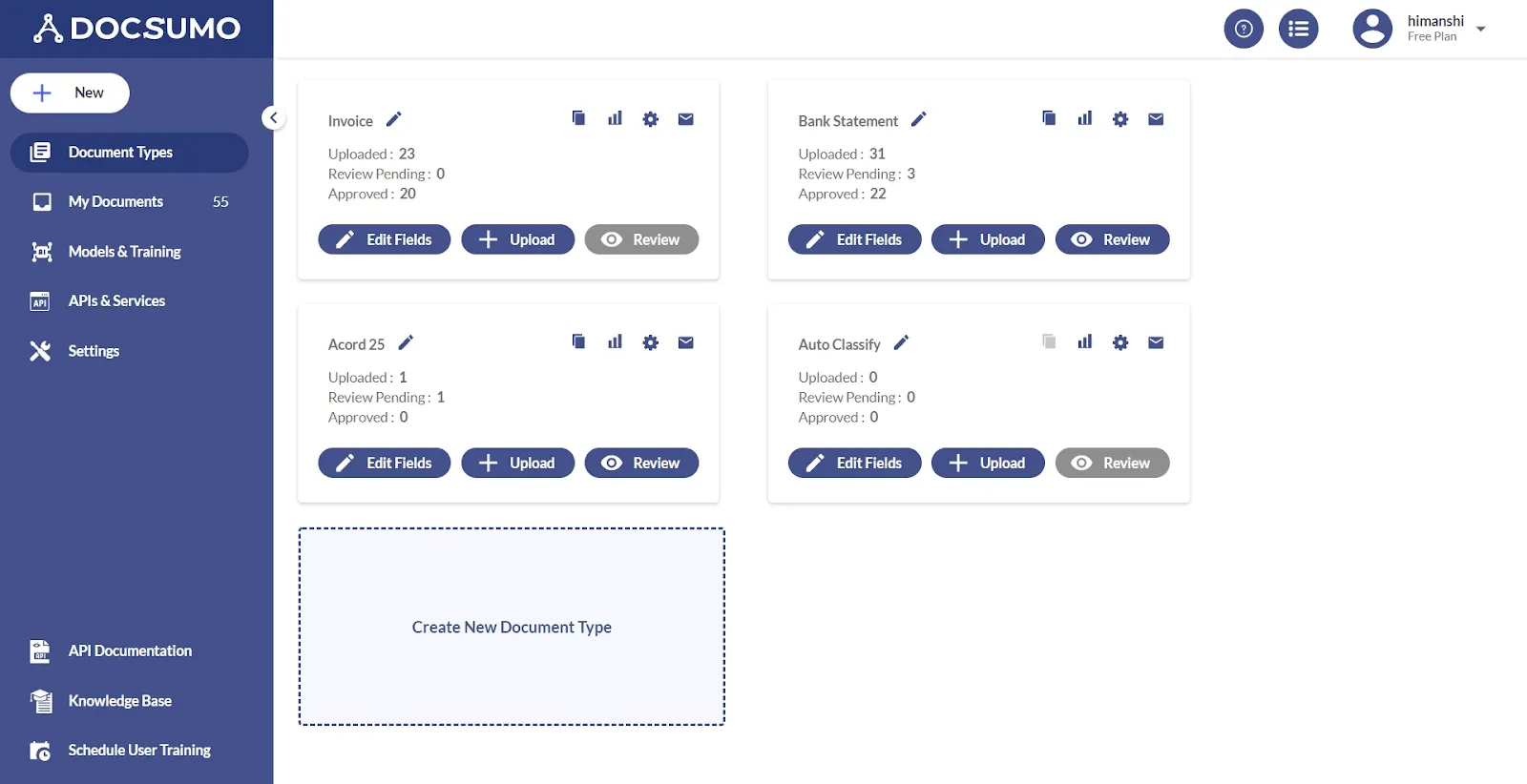
3. Go to Document Types > Create New Document Type. Upload your first new document
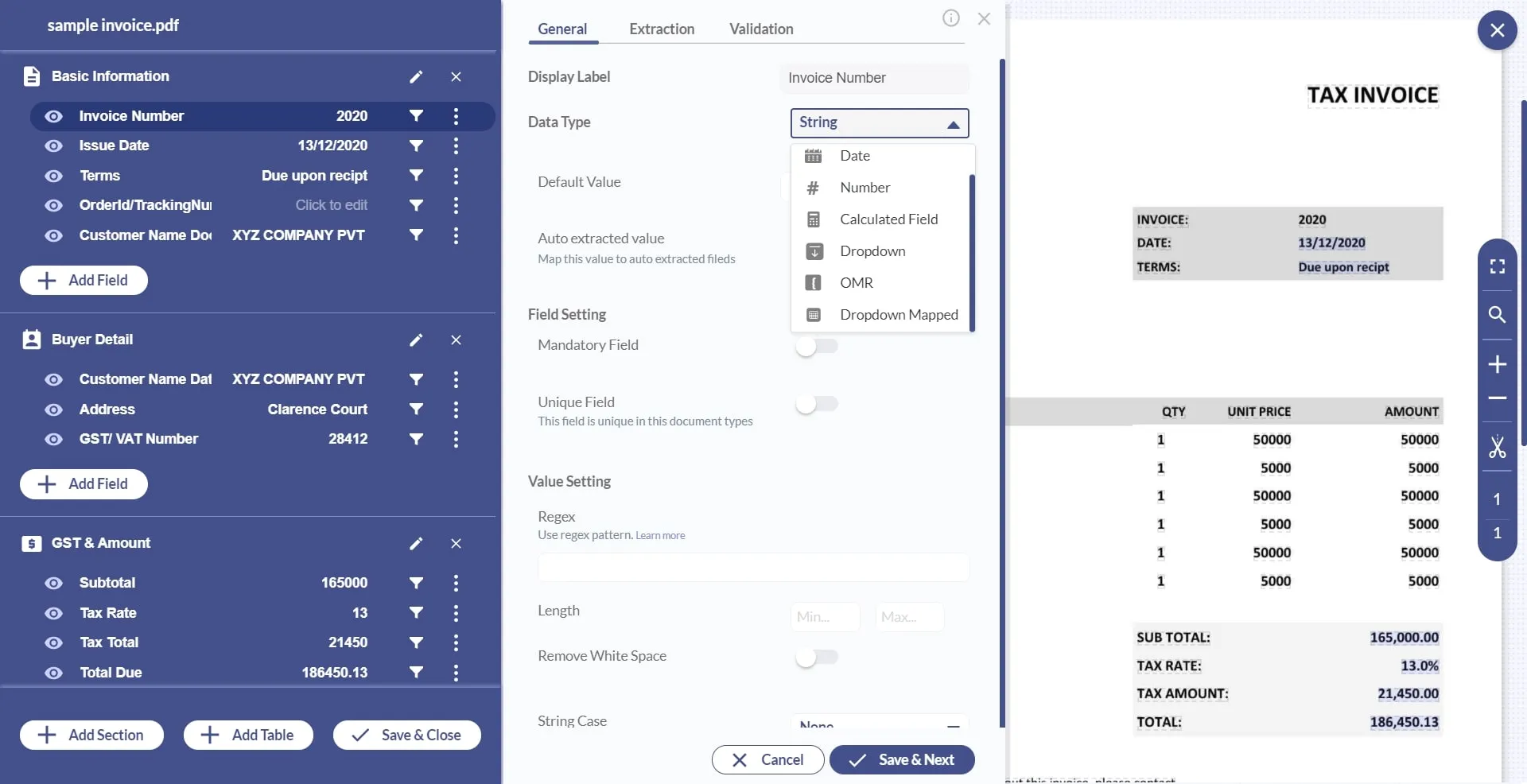
4. Set your key identifiers and choose the appropriate data types for each field. This step involves a drag and drop approach where you create bounding boxes to help the model detect different fields on the document. You can refer to our key value pair extraction guide for a complete overview of how key-value pairs work.
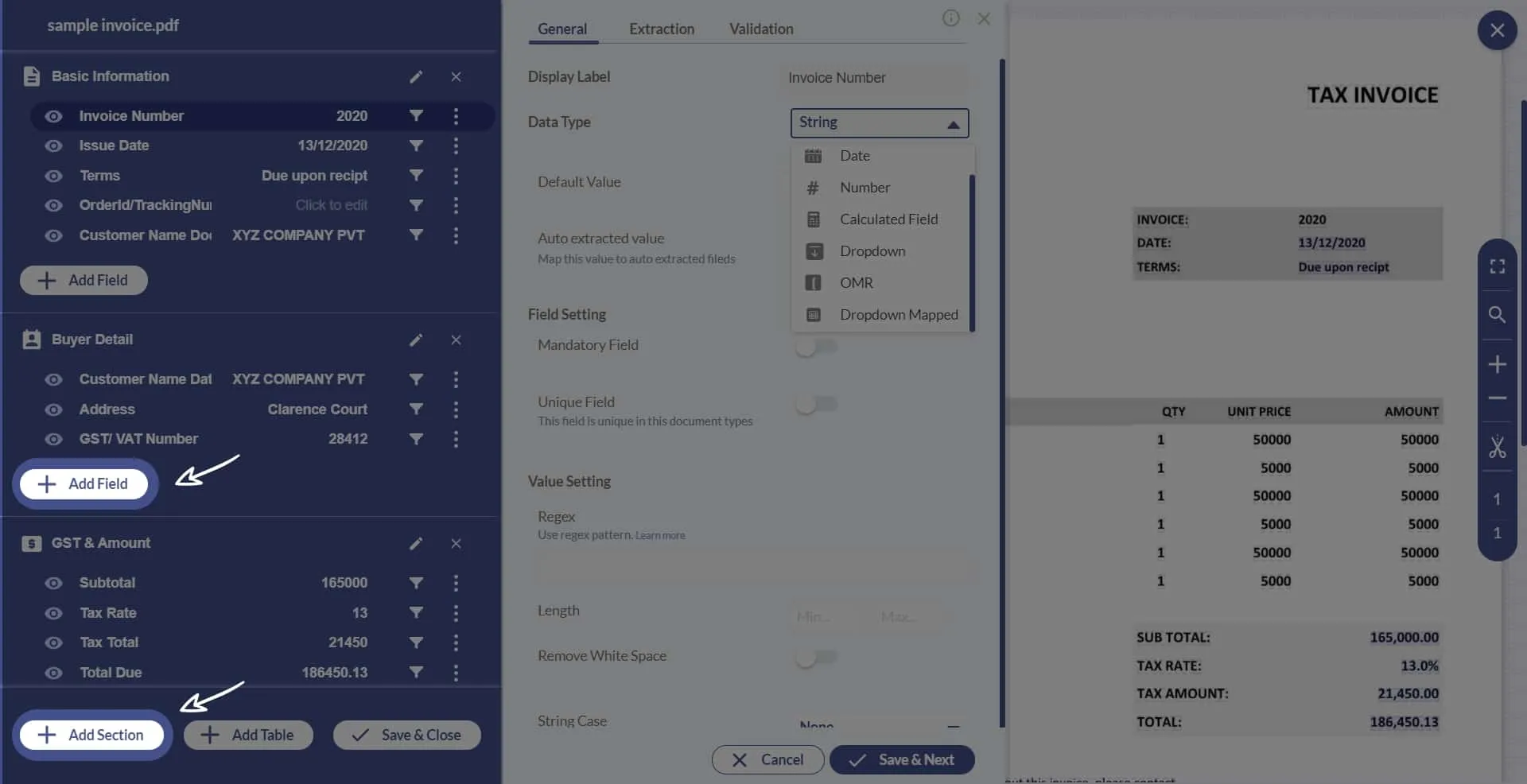
5. Select the ‘Add field’ button to add more fields and define the data types for each. To create a section, click on ‘Add Section’.
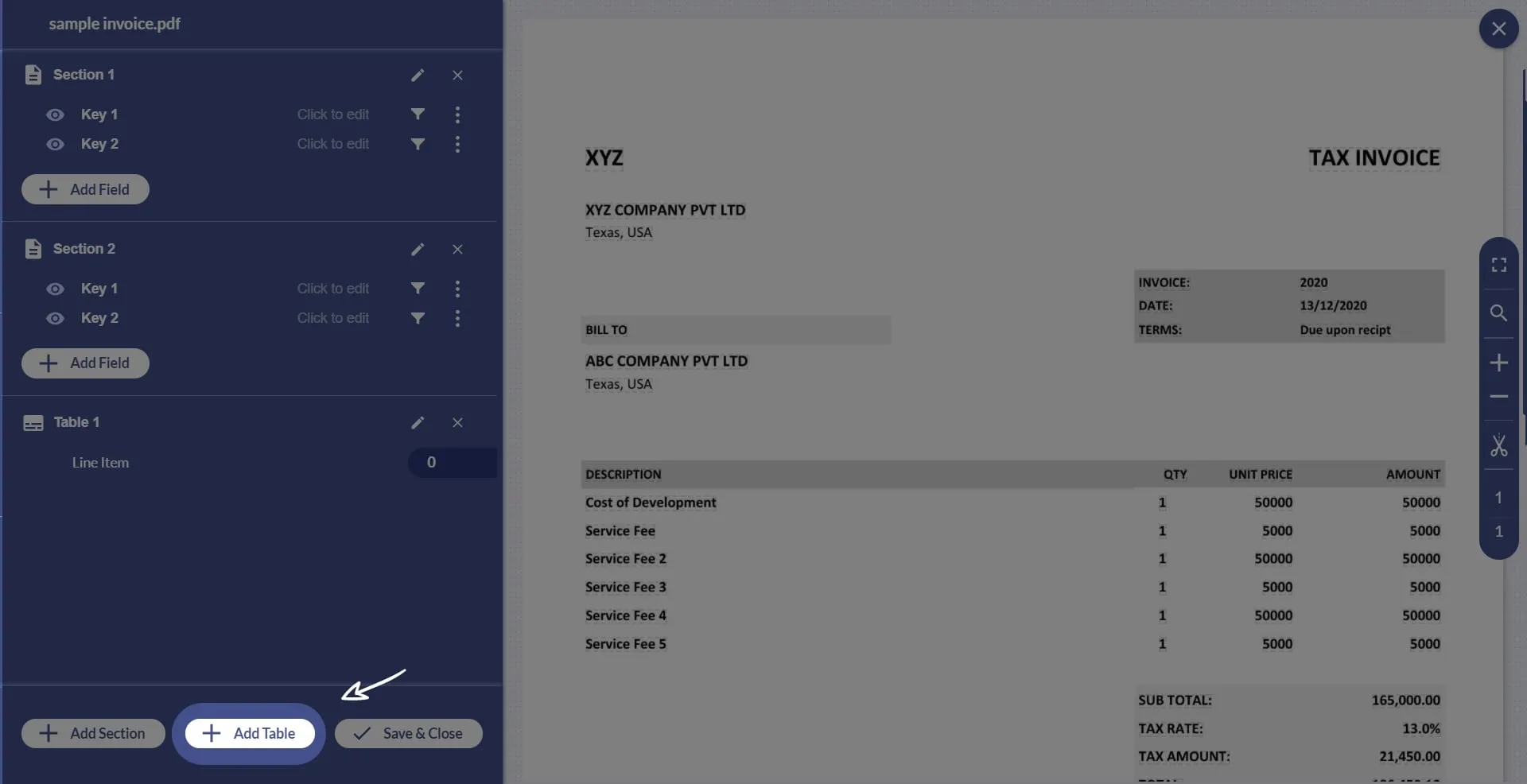
6. Each section is a different part of your document and each section has its own set of key value pair fields. Similarly, you can extract line items in a different section with ‘Add Table’.
7. Click on Save and Close. Docsumo will display a pop-up asking if you want to apply the changes to all your new documents or to both existing and new documents. Select whichever is appropriate for your needs and finish.
8. At this point, the document is annotated. After that, go back to 'Document Types' and 'Upload' at least 20 document files. Once uploaded, you can 'Review' the uploaded files. All the uploaded files have keys listed and you can find values extracted for some of them. If you don't see the value extracted for a data variable, help the software to capture the value for it.
9. Once all the fields are extracted accurately, 'Approve' it. Repeat the process for few documents. After doing it for a few documents, the software starts to capture data for all the fields accurately. Go ahead and 'Review' and 'Approve' at least 20 documents.
Use your trained API to review data extraction
To use your newly trained API for reading and extracting information from documents, simply follow these steps:
1. Log in to the Docsumo dashboard
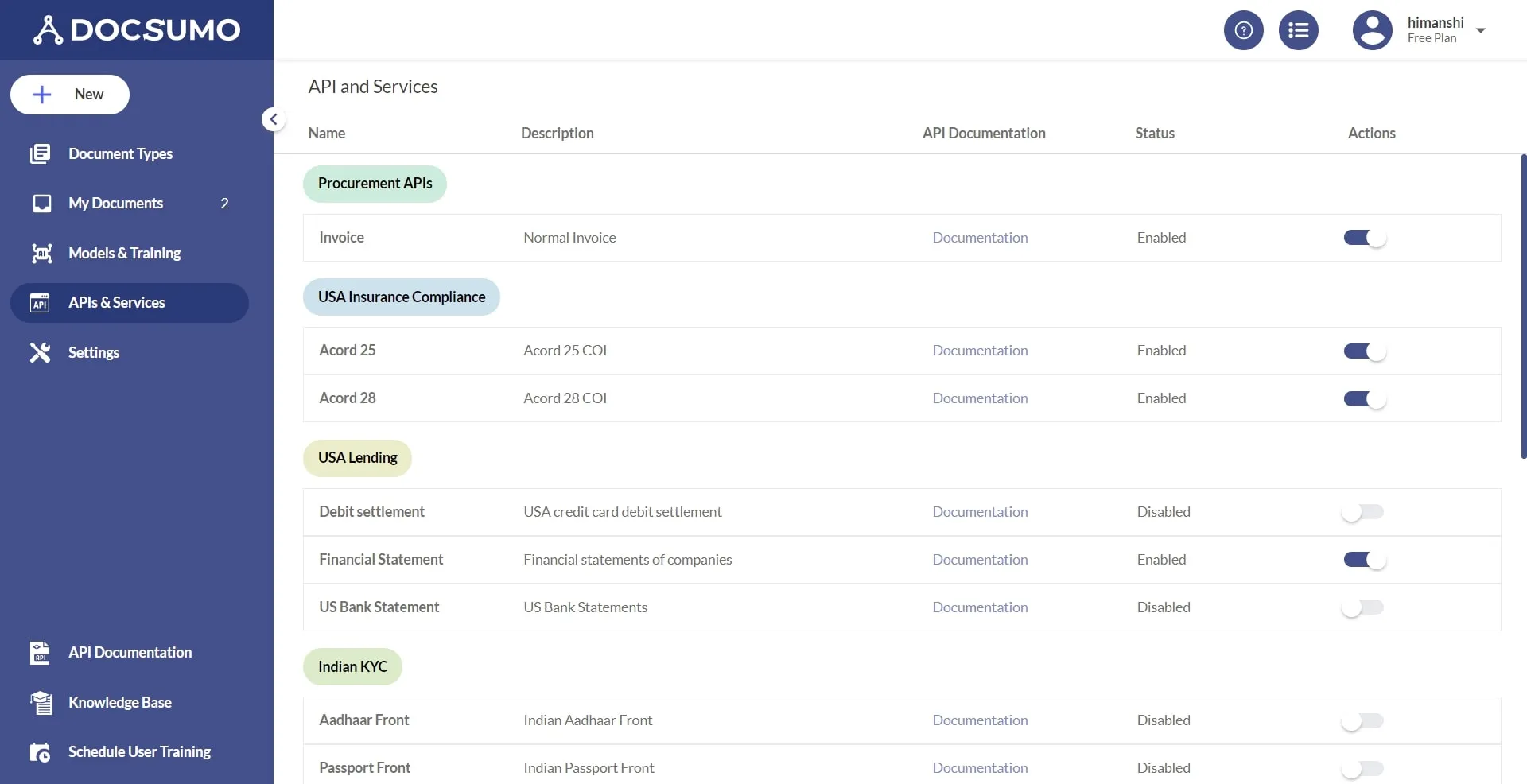
2. Select APIs & Services
3. Choose the appropriate API model for your document type. If you’re planning to upload Acord Form-25, you need to select the ‘Acord 25’ API. Under Actions, toggle the button and make sure it is set to Enabled.
4. Go to Document Types, find your API module and hit Upload
5. The trained Docsumo will automatically read your document and structure the information. If any errors are found or any details are missing, it will flag them and alert you instantly
6. You can click on Review to do a manual review of your documents after the automated extraction is done.
Conclusion
And that is how you train a new API and teach it how to read new documents. You can repeat these steps to create new document types for different purposes. Docsumo supports bulk uploading documents and has batch processing benefits too. Once you have your pre-trained APIs set up and running, it takes mere minutes to get your documents processed and converted into electronic formats.
The best part about using Docsumo is that you can convert your documents into different file types such as JSON, XML, and CSV. So, what are you waiting for? Improve your document processing times and enjoy 99% accurate automated data extraction using the power of Docsumo APIs.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.

.webp)
