
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.
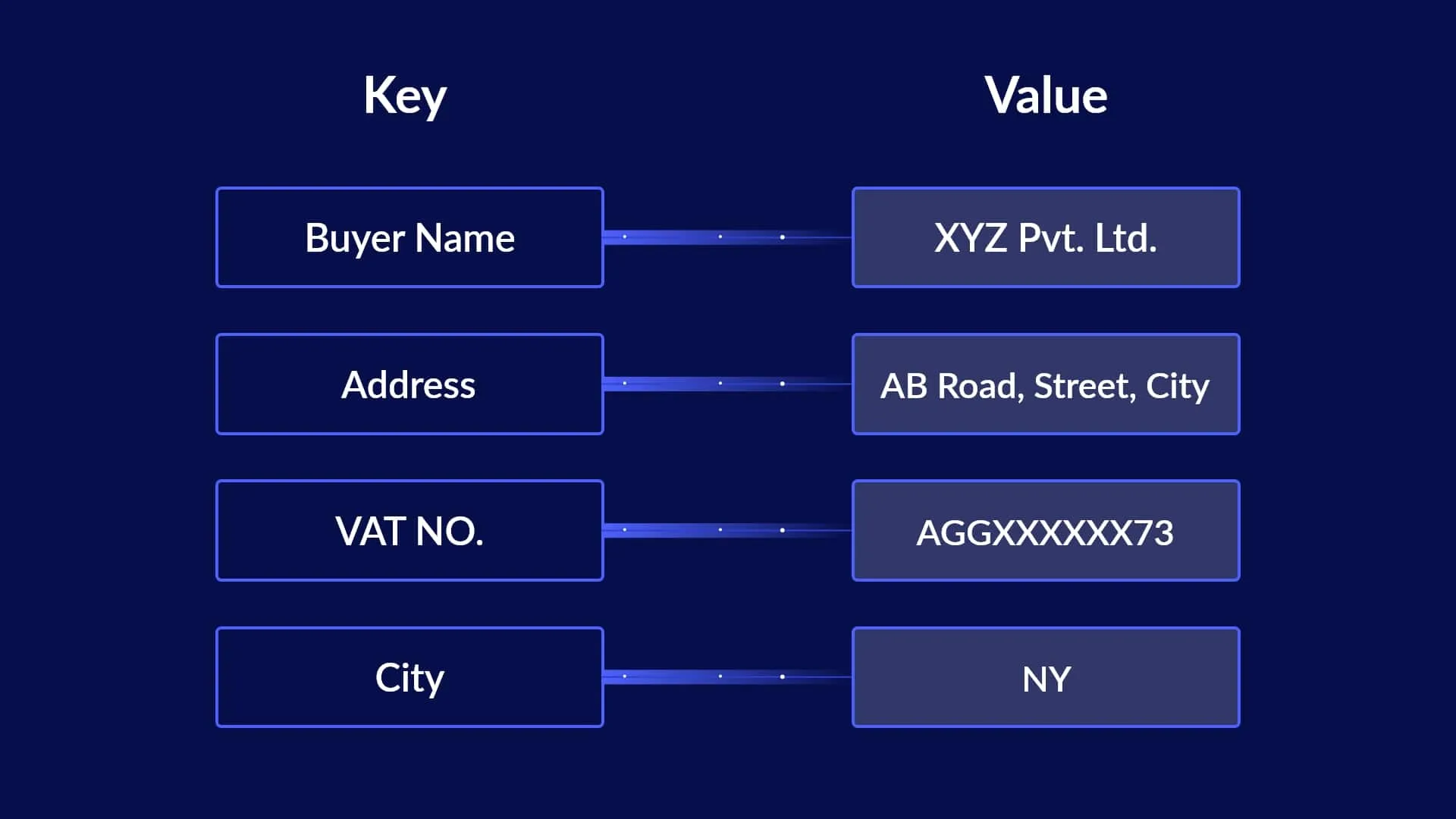
A key value pair is a data item which is linked to an attribute value. The content is present within the attribute value while the data item is treated as the ‘original key.’ Businesses find it useful to extract key-value pairs from different structured/semi-structured/unstructured documents for analysis and decision making. Often this is done manually, but with the advent of automated data extraction technologies, businesses are automating this process for improved accuracy and increased productivity.
In this article, we discuss the basics of key-value pair, limitations of manual key-value pair extraction, and how technology overcomes these limitations.
So, let's jump right into it:-
A key value pair is essentially a set of two data items – a key and a value.
The value corresponds to the key, with the key being marked as the unique identifier.
Multiple key value pairs together make up a key value database. The key for data items in these databases are defined as sets of unique identifiers each of which have a unique pairing. The location of the value is identified through the unique identifier in a key-value pair.
For example, for Grain Company the 'Vendor' field would be the key, with the value being 'AB Grain'.
Likewise, key-value pairs make up a collection of fields which provide key information about documents. These details are processed and entered into organizational databases for safe record keeping.
However, here lies the main challenge.
Extracting data and entering it automatically to online forms for faster processing.
Below is a list of examples of different key-value pairs across different documents and industries.

Key-value pair fields for invoices would be data items such as:
Survey forms consist of key value pairs in a question and answer format.
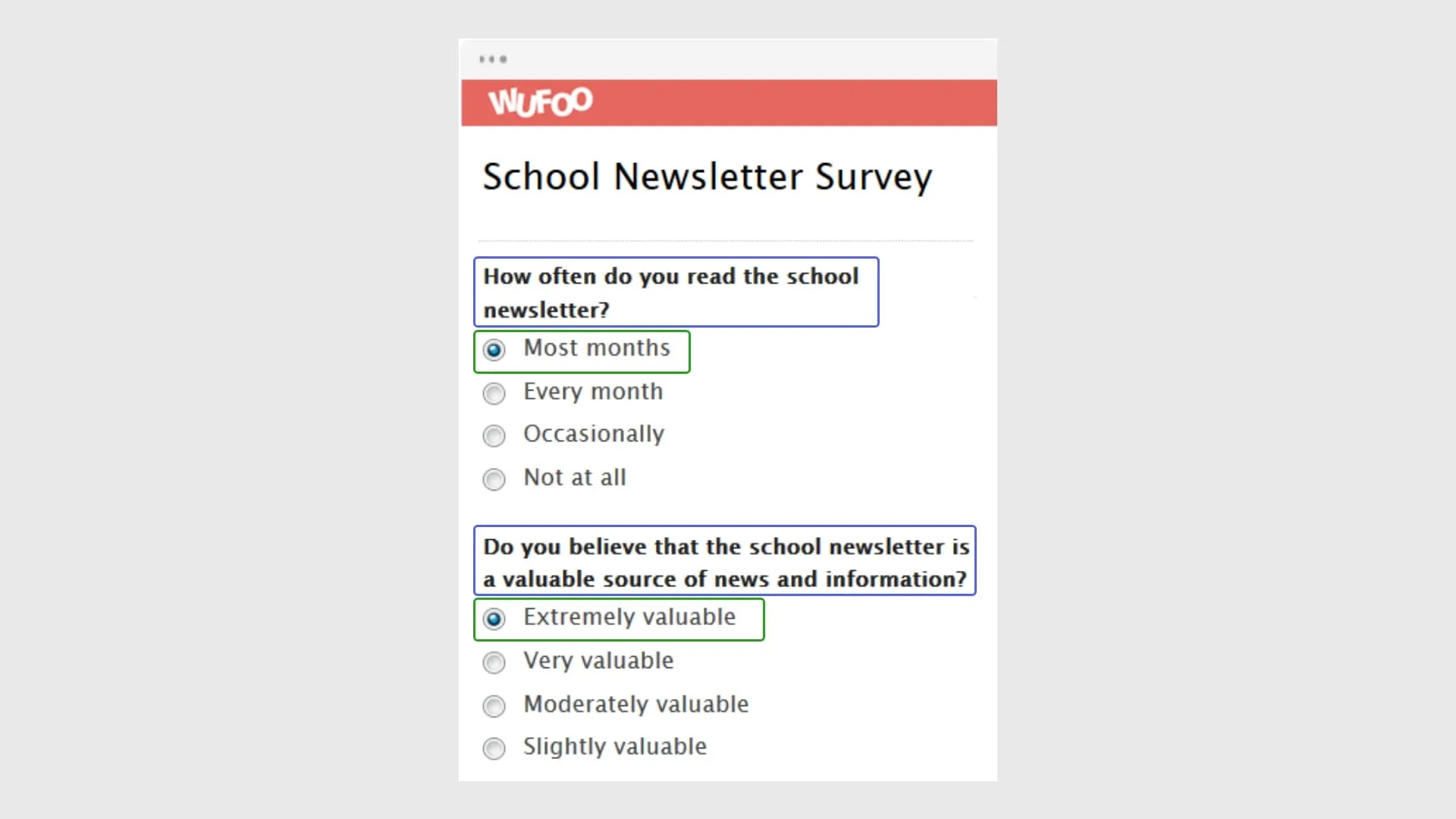
The key would be the main question, with the values being the answer of choice.
If it’s a feedback survey, the values would be custom or entered manually by the user instead of selecting from a list of options.
Government documents like passport and driver’s license have sensitive data stored on them in the form of key-value pairs. A classic example would be a passport page where the key-value pair fields would be:
It is possible to manually extract key value pairs but there are limitations. Here is a list:-
Taking the time to sit down and go through numerous documents is a tedious task involved in manual key value pair extraction. The enormous volumes of data can overwhelm administrators.
If the person extracting these fields and entering information makes a mistake, it is going to end up organizations losing customer trust.
There could be fields blurred out, left empty, or information missing from forms as a result of manual entry. Humans make mistakes when they least expect it, especially when going through so many documents.
Manual key value pair extraction is a slow and time consuming process. Processing speeds are lower when comparing manual key value pair extraction with automated mechanisms.
For those who are dealing with unstructured data, documents have to be formatted on top of manually extracting the fields. There is a risk of data duplication and redundancy in records as well through manual extraction methods.
Key value pairs can be extracted days by using a combination of ICR and OCR technology. Methods to automate key-value pair extraction are listed below:-
Named-entity recognition is a sub-task of information extraction that tries to locate and classify named entities in unstructured text into predefined categories such as person’s name, ID number, address, organization etc. This comes handy in key-value pair extraction in unstructured/semi-structured documents.
Approaches to execute Named-entity recognition:-
i) Multi-class classification
ii ) Conditional Random Field (CRF)
i) Bidirectional LSTM-CRF
ii) Bidirectional LSTM-CNNs
iii) Bidirectional LSTM-CNNS-CRF
iv) Pre-trained language models (Elmo and BERT)
Fast Region-Based Convolutional Network Method is used for object detection from forms which ensures a 66% precision rate. Object detection techniques are used in computer vision primarily but are being increasingly adopted in automated document extraction. Bounding boxes are drawn around entities and neural networks automatically interpret document layouts.
Text can be extracted from images using intelligent OCR such as locations, addresses, company names, persons, and these details can be organized into structured data.
1. Visit app.docsumo.com and log in using your user credentials.
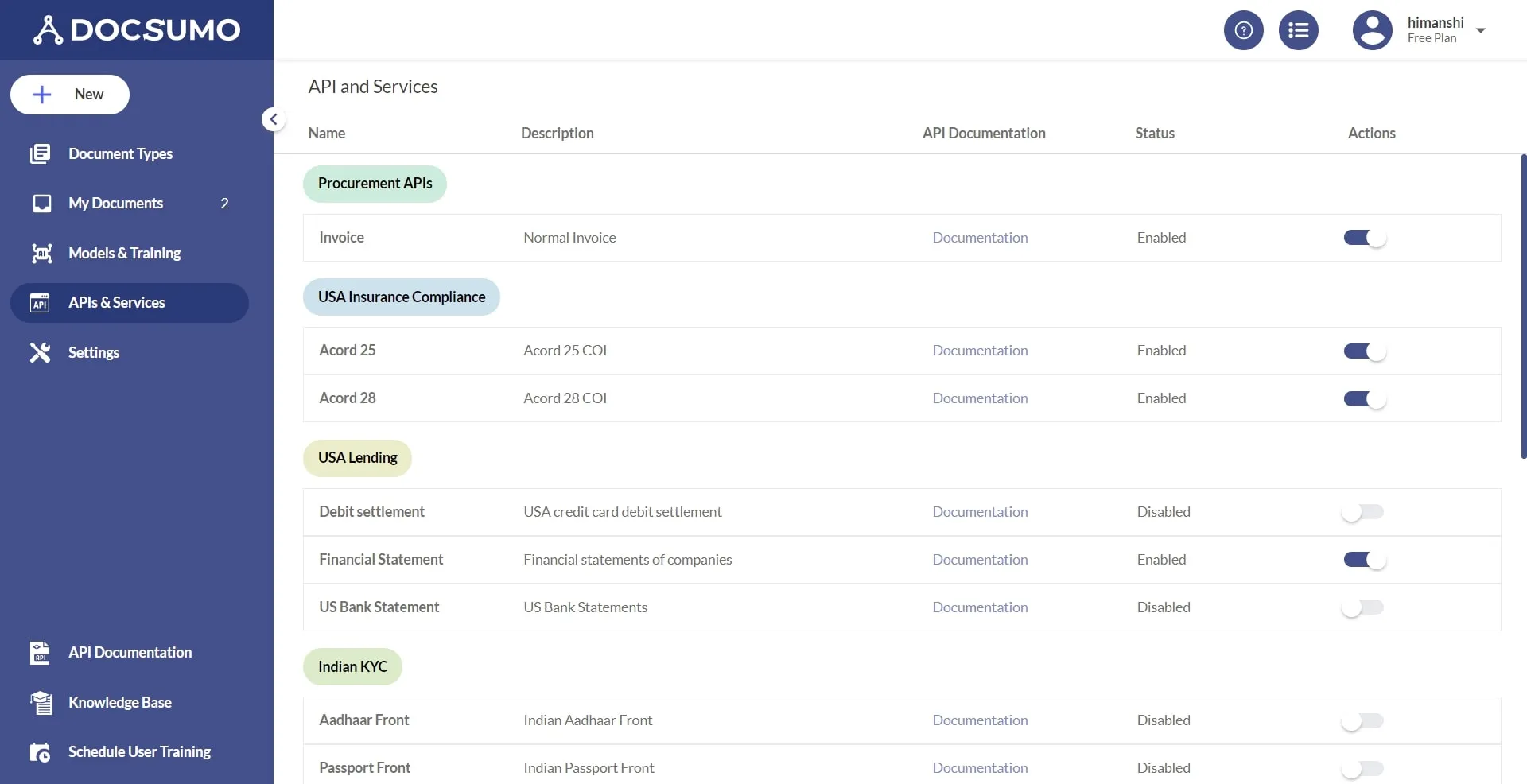
2. Click on APIs & Services and you will get a list of pre-trained APIs which you can use for extracting key value pairs. For example, if you want to extract information from Driver’s License, you have to select the Driver’s License module and so on.
3. Go to Document Types after selecting your pre-trained API. If you don’t have a pre-trained API and need to define a new document type, go to the next step. Click on 'Create New Document Type'. You will get this screen.
4. After the document is uploaded, define new fields that are your key identifiers.
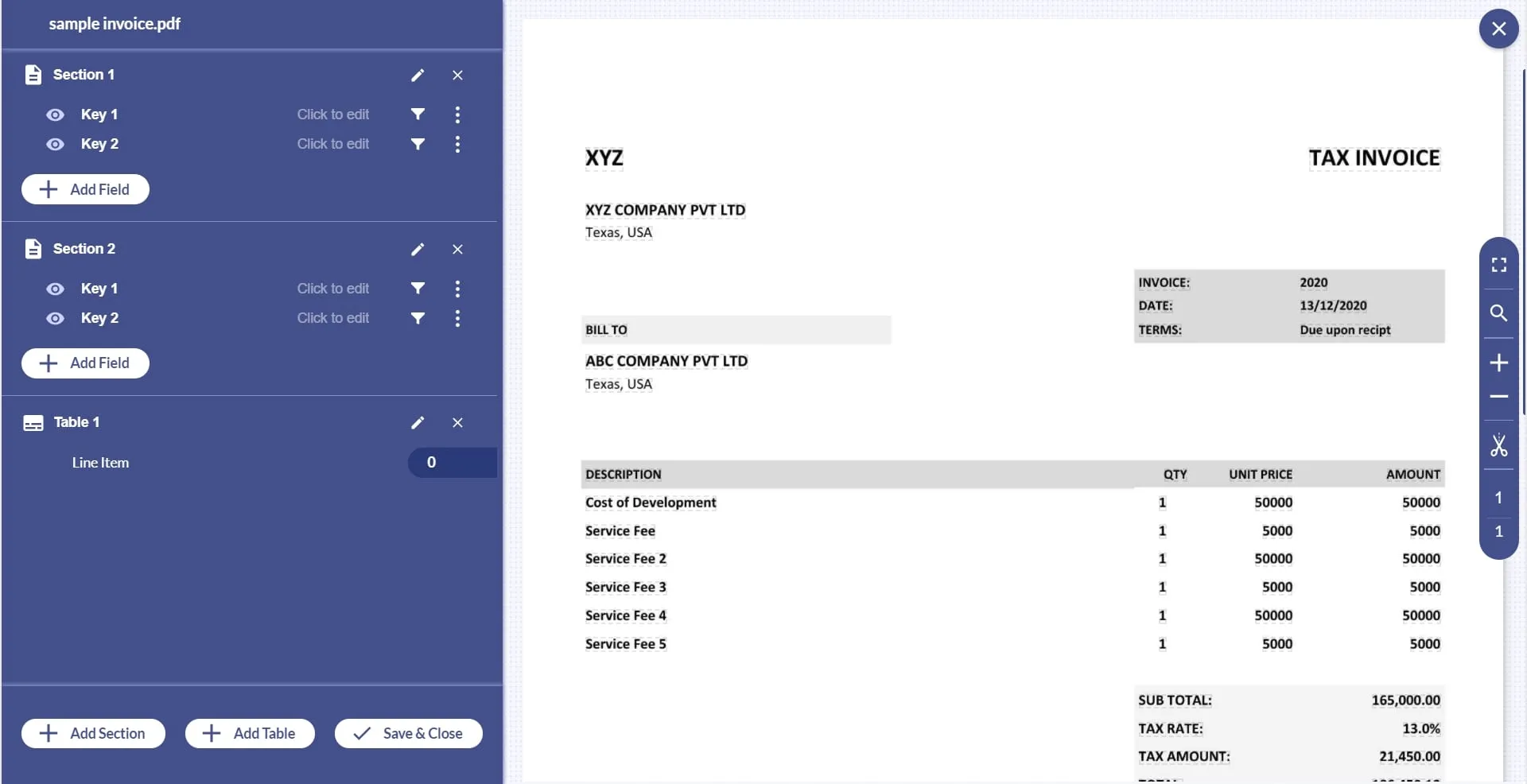
5. Click on “Add field” and specify your data type. You will get different options depending ranging from String, Date, Numbers, etc.
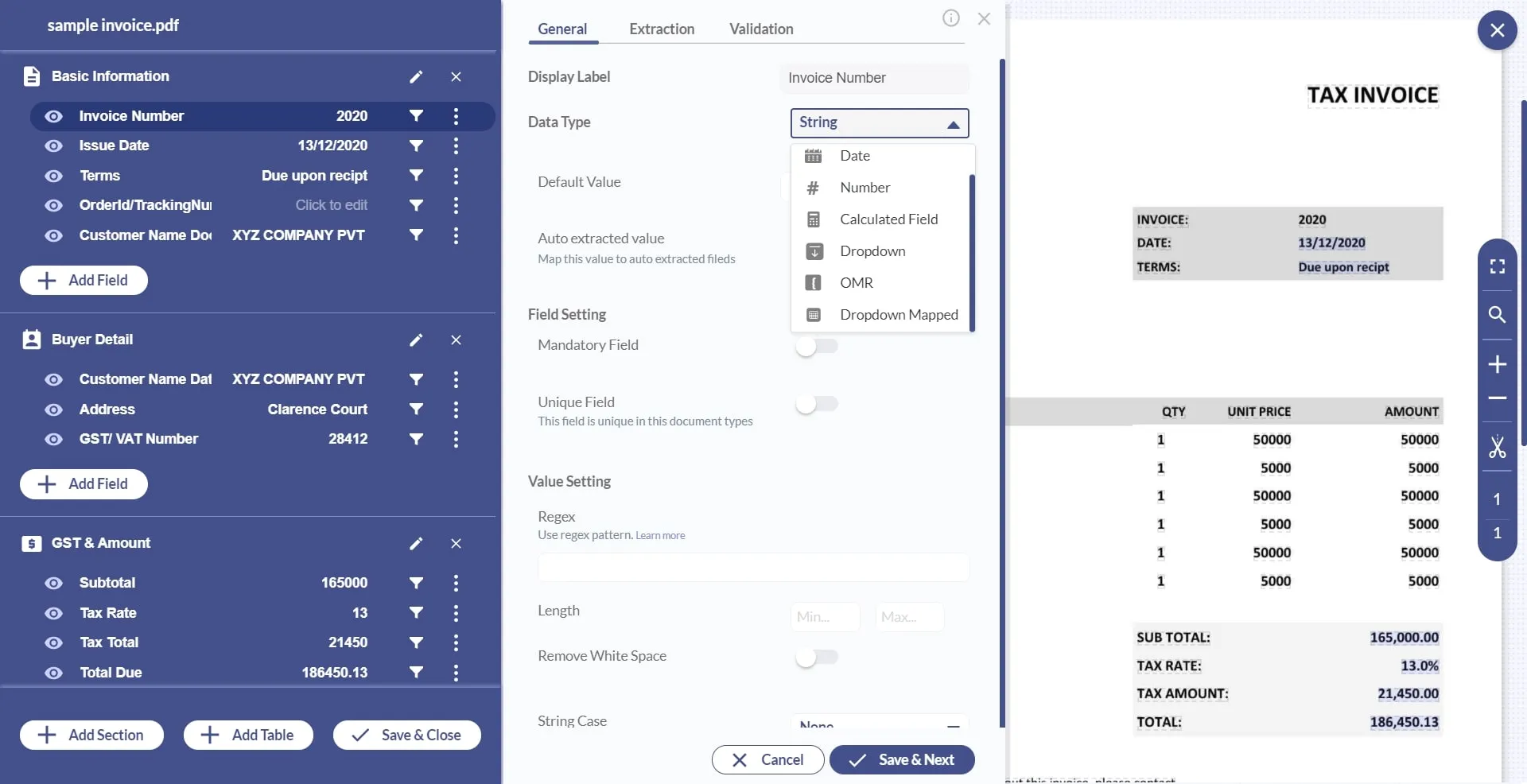
6. Select “click to edit” and draw a bounding box around the value you want to capture.
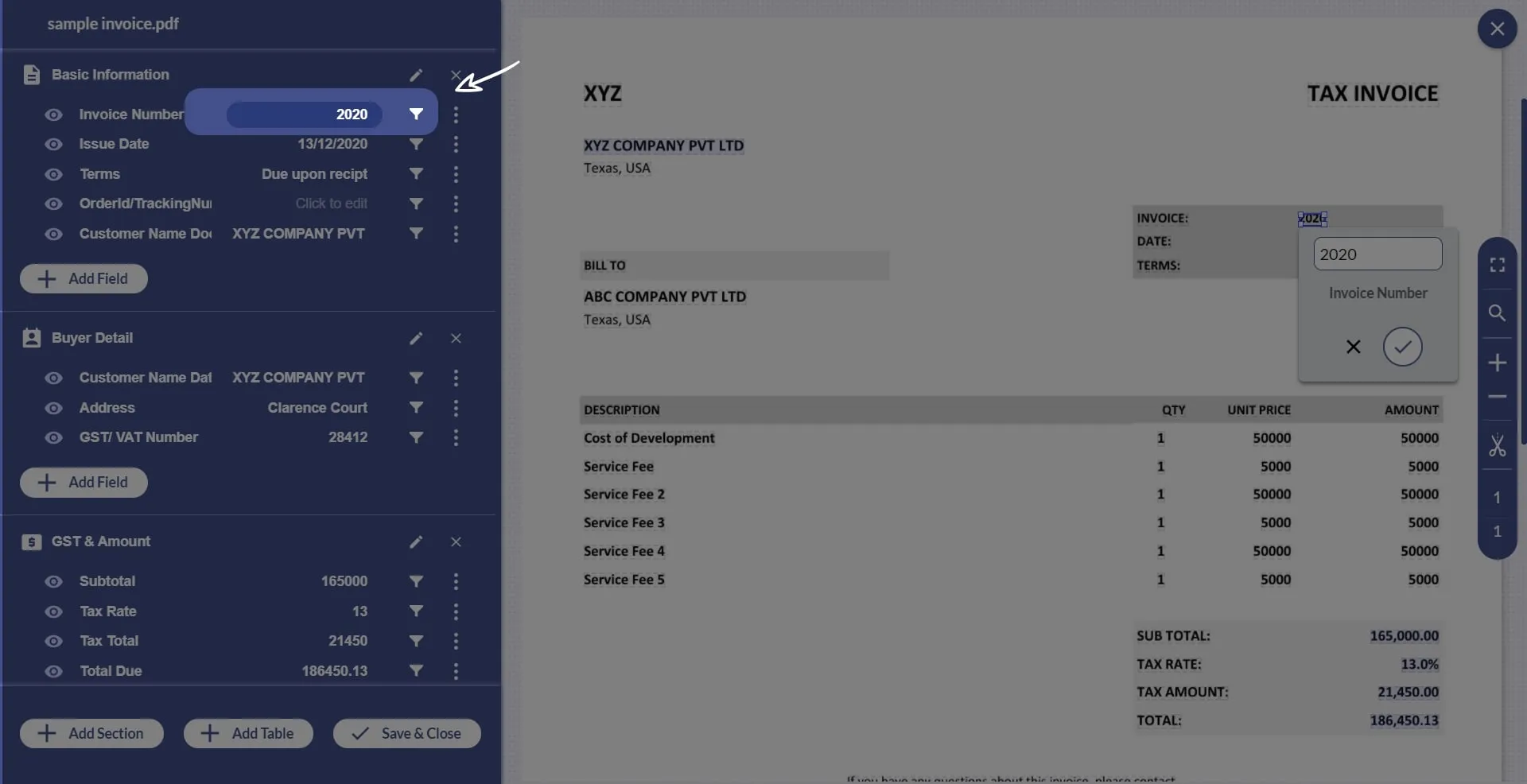
7. Repeat the process for all the key-value pair. After that click on ‘Save and Close’ and decide whether you want these changes to be applied to new documents only or the existing ones as well.
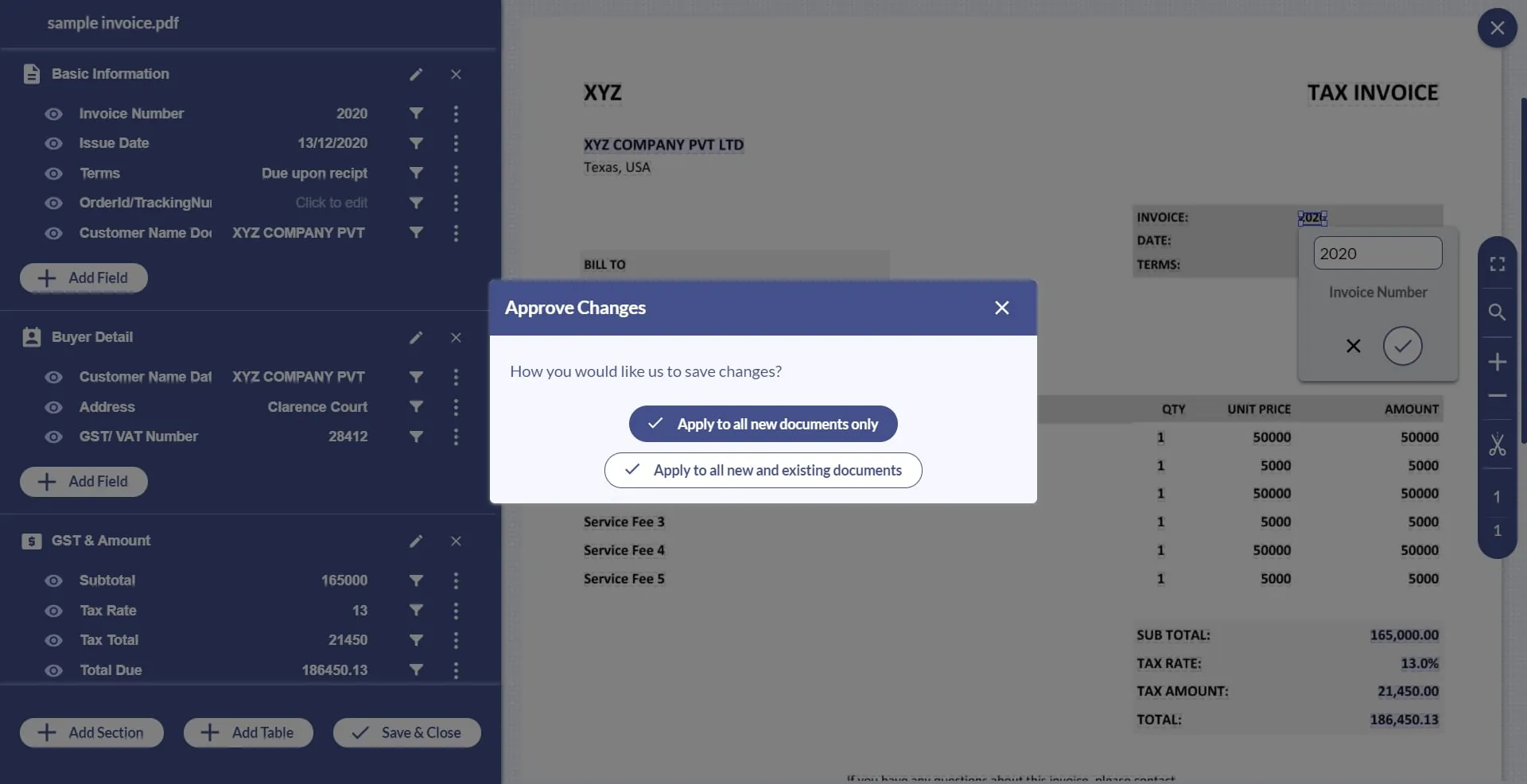
Your custom API is now trained. Now all you have to do is upload your document type to the API and it will automatically extract the KV pairs for you. You can click on review after the automated data extraction is done for reference.
As a business, if you are trying to automate key-value pairs extraction from structured/semi-structured/unstructured document types, give us a call. This will not be a sales call but an attempt to understand your industry use-case and lead your way!
.webp)