
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.
As most of an organization's information is available in an unstructured format, processing it requires an automated system that can handle documents with minimum human interaction. OCR is one such technology, but its scope is limited as it requires human interaction and is highly dependent on the layout and structure of the document to be processed.
These limitations are overcome by Intelligent Data Extraction.
Using artificial intelligence, the Intelligent Data Extraction technology extracts data from documents and transforms it into useful information through the extraction process. It functions as a singular tool for extracting information from any type of document and aids in optimizing company operations.
Intelligent data capture is the process of automatically reading and capturing vital data from incoming data sources utilizing artificial intelligence and machine learning. It is able to extract information from printed documents, scanned images, and electronic documents in multiple file formats.
The retrieved data is then routed through the appropriate channels, where it is checked and given to the appropriate users or workflows.
Before we get into how intelligent data extraction works, let’s look into the limitations of optical character recognition technology.
Traditional OCR was never intended to be a solution for dynamic data extraction. It was first created to translate written characters into speech for the blind. Eventually, the technique was used to read and recognize black text on a white backdrop. Therefore, OCR presents some difficulties.
Here are the five most significant drawbacks of conventional OCR:
Text recognition and extraction quality are directly proportional to the quality of the picture input provided to the engine. For example, when the character height is less than 20 pixels, the precision decreases considerably.
Traditional OCR needs the use of templates and rules. The engine must be programmed to take data from the right fields and lines in accordance with strict regulations. Consequently, it is unable of handling the variety of documents and struggles with unstructured ones.
Due to its reliance on templates and rules, conventional OCR lacks numerous automation options. If you want to extract structured data from bills, for example, you would need a separate rule for each individual data field. And as you are aware, invoices come in a variety of forms and formats, resulting in several restrictions.
Adding more rules would necessitate additional training data and resources for the OCR engine. With the typical approach, there will always be additional regulations to establish, thus this may create a significant bottleneck.
As additional rules and algorithms are required to improve accuracy, classical OCR may become quite costly. In addition, the creation of these rules and algorithms does not always ensure a high-quality result because picture input quality is also a factor.
When basic papers with few alterations are scanned with standard OCR, the result is frequently very accurate. However, several organizations must process a variety of documents inside their processes.
The more the document diversity, the greater the difficulty. Due to the fact that the conventional OCR engine is taught with templates, it cannot keep up with a wide range of documents.
OCR and IDP, two of the most prevalent approaches, allow automated processing. Here is a comparison of the advantages and disadvantages of several document processing techniques:-
Intelligent Data Extraction functions similarly to the human capacity to read and recognize text patterns and characters. Typically, individuals would read the text and then manually enter the extracted information into a system, datafile, or database.
It takes a somewhat different approach. The technique improves the quality of a scanned text or picture and extracts collected data through a series of processes. Manual labor requires additional time and is more susceptible to human mistake.
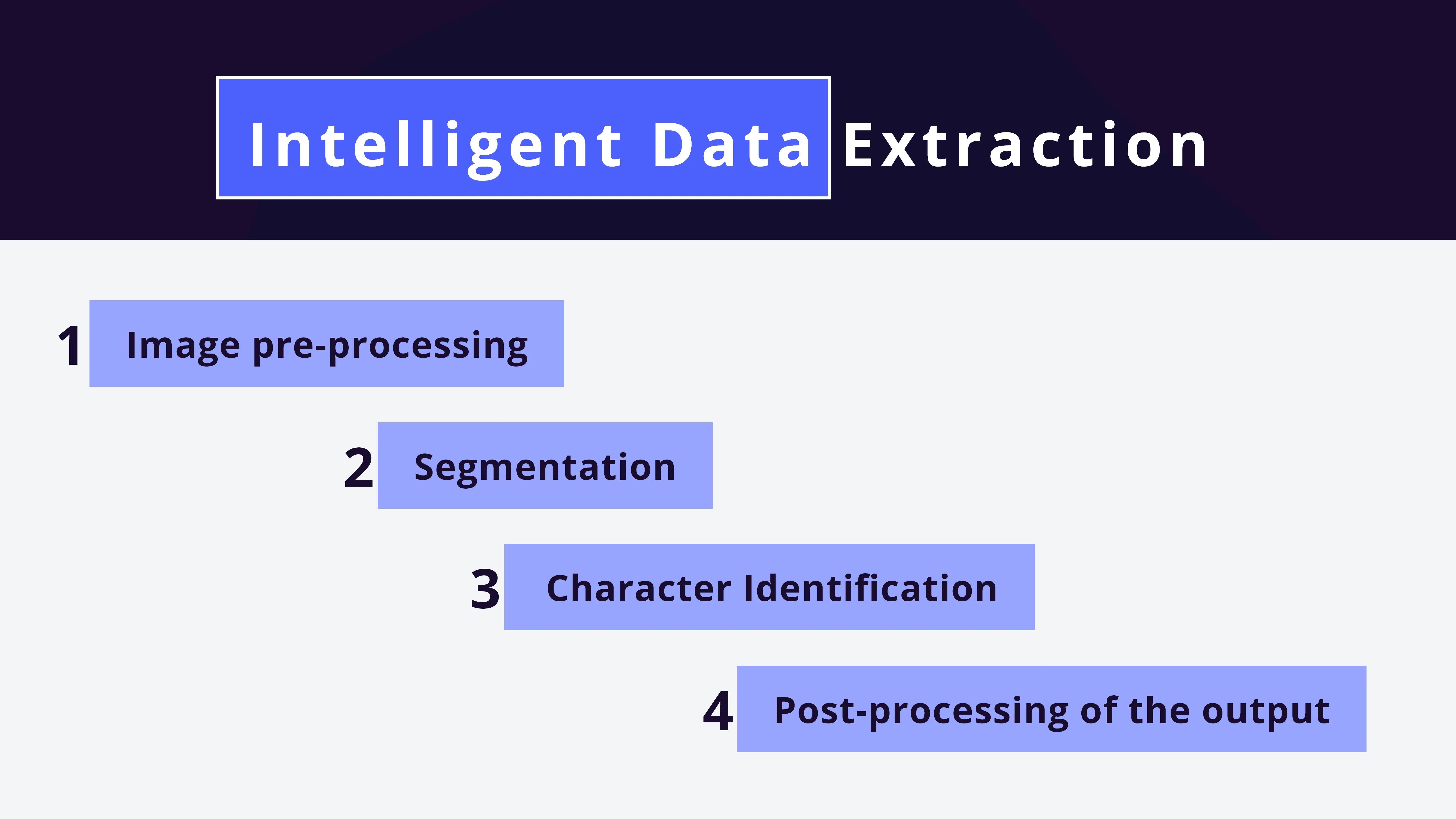
Let's take a closer look at the following Intelligent Data Extraction steps:-
To ensure reliable data extraction, the picture quality must be improved. Image enhancement is frequently referred to as the image preprocessing phase. The greater the clarity and quality of the image or scanned document, the more precise the data produced.
In the pre-processing phase, the OCR engine searches for and fixes faults automatically. These approaches are frequently used to improve photographs or scanned documents:
The process of identifying one line of text at a time called segmentation. Segmentation includes the subsequent steps:
In this stage, an image or document is divided into sections, subsections, or zones. Following separation, the characters inside them are identified.
Two methods are employed during the character recognition step:
Step 4: Post-processing of the output
This stage focuses on the procedures and algorithms that increase the accuracy of data extraction for the best possible outcome. The data is identified and then, if required, corrected.
To conclude the post-processing step, the collected data is evaluated against a word or character library for grammatical checks and contextual considerations.
Intelligent Data Extraction improves the efficiency of your organization's data collection and use process from the very beginning. It accomplishes this by harvesting data in real-time, delivering it to the lead systems, and providing important information to the end-user nearly immediately.
Here are some ways in which your company might profit from Intelligent Data Extraction.
Using Intelligent Data Extraction, manual processes that consume time without contributing significantly to the overall process may be automated. This will allow staff to devote more time to high-value, crucial jobs.
Traditional methods of data input and processing raise operating expenses and need the expenditure of extra human resources as the volume of incoming data grows. Printing data for processing and storage increases an organization's overhead expenses. Digitizing all incoming information, whether by email, physical paperwork, or even mobile phones, helps reduce these overhead expenses. Since less human resources are spent manually inputting and validating huge datasets, the time may be redirected to other important duties, resulting in improved organizational growth without incurring additional costs.
Intelligent capture provides a single point of capture at which artificial intelligence may learn to recognise different types of documents and the locations of crucial data inside them. As more data is handled, the process becomes smooth and the efficiency of such procedures grows.
As an increasing number of firms adopt a remote working paradigm, intelligent capture facilitates dynamic engagement through a shared data set without the requirement for co-location. Thus boosting the accessibility of distant personnel and the synergy between teams and departments.
Intelligent capture facilitates dynamic engagement via a shared data set without the requirement for geographical proximity. Thus boosting the accessibility of distant personnel and the synergy between teams and departments.
Content routing restricts access to specified data to those who are allowed to examine and verify it. It guards against data breaches by encrypting incoming data and against data loss by securely recording and storing all incoming data in a single location. This enables a business to adhere to security regulations and reassures clients that their data is secure. The audit trails are entirely public and easy for future authorities to access.
Intelligent data capture software can produce higher quality data due to error-free categorization and characterization of inbound data. In addition, the data is connected to an audit trail, which ensures that no compliance standards are breached with regard to the data. Digitization of the papers enhances security and enables effortless tracking, making compliance effortless.
Intelligent capture enables a single platform to serve department-specific users and procedures. Thus, the process of data capture, validation, and routing is streamlined, and the learning curve for various applications within the same business is avoided.
Streamlining data collection enables quicker and error-free information input through automation. Eliminating human error, implementing a constant machine learning algorithm to make the process smoother and ready for the evolution of incoming data, and allowing human resources to focus on critical tasks rather than manual ones all contribute to an increase in the organization's overall efficiency.
Intelligent Data Extraction enables firms to take the appropriate initial step toward establishing an improved data management procedure. It is also a prerequisite for developing an effective automation process for your organization as a whole.
Intelligent capture collects and analyzes data using several toolkits to extract vital information and route it to lead systems. Machine learning also enables intelligent data capture software to educate itself to discern between different types of data and accurately categorize standard and unique data, therefore accelerating and improving the process over time.
Save 100+ hours a month by automating all your low-impact tasks so that your team can prioritize faster and accurate business decisions, every time.
Get Your Free Trial Today
.webp)
.webp)
.webp)
.webp)