The problem with historical OCR processes is that their accuracy lies between 70%-80% for a high-quality image. While that may seem high, it can cause significant inaccuracies if used on a large volume of documents or sensitive documents like invoices. Imagine losing 2% of the value on every invoice you generate because your OCR system is not accurate!
Intuitively, when you think about OCR, it seems like an NLP problem because you are dealing with language and text. Right?
Well, the reality is that OCR is highly dependent on image processing, visual computing, and machine learning – the entire AI umbrella except for NLP.
a. They begin with identifying blocks of texts in a specific area – whether in an image or a document.
b. Then, they determine each character in that block.
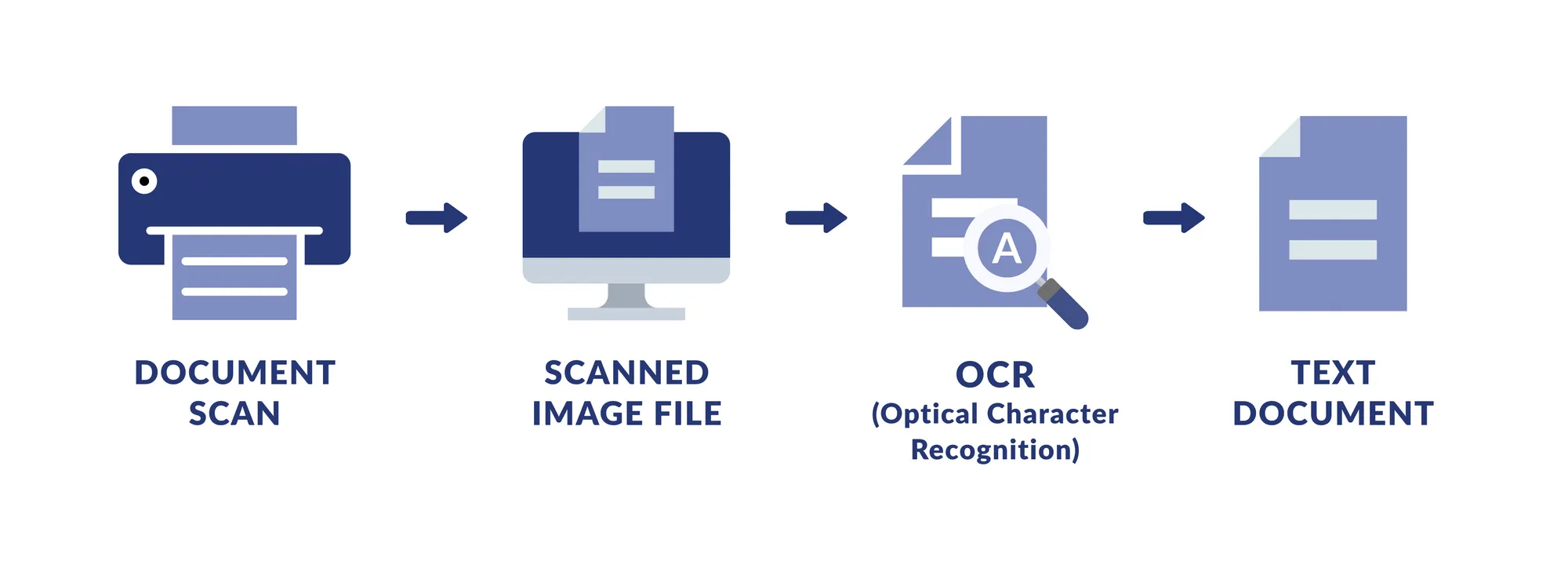
You can use images and PDFs as input to an OCR platform and get JSON or XML files ingestible by the database as your output, ready to be analysed.
The role of deep learning and OCR in image processing
Generally, leading deep learning algorithms like Single Shot Detector, Mask R-CNN, and YOLO (You Only Look Once) are used for OCR. These are some of the most sophisticated object recognition, segmentation, and processing algorithms. They do a decent job of giving an accurate OCR output.
However, there is one key challenge. Some algorithms that work well with the family of objects like vehicles & animals are not suitable for recognizing text in an image. The reason for it is quite apparent – the character detection process can easily get distorted if the algorithm has the option to classify it as an animal or a vehicle instead of just a textual character.
The more reliable forms of deep learning applications for OCR are:-
1.Convolutional recurrent neural networks
A typical Convolutional Neural Network would add convolution and pooling functions to see how the processing of two images can efficiently result in a third image. A CRNN amplifies that process. It begins with segmenting the entire image into feature vectors. This way, instead of processing and analyzing the image as a whole object, it works on having smaller chunks of features. Once the feature vectors are bifurcated, they are run through a bidirectional long-short term memory (LSTM) cell.
LSTMs are better than Markov Models and even typical RNNs because they are not sensitive to the gaps in the data being processed. Hence, the feature vectors are processed as data, and since there is no gradient error issue, the LSTM cell is able to store the information on a subjective basis. This allows it to work better on predicting the relationship between the feature vectors.
The entire output of the LSTM cell needs probabilistic processing. This is critical because since we are dealing with text, there would be redundant characters, and yet the sequence has to be accurate for worthwhile output generation. Hence, the LSTM cell's output is run through a transcription layer that sharpens the output to establish accurate relationships between feature cells and recognize text out of the image.
2. Recurrent attention model (RAM)
RAM's working methodology is strongly captured in the proverb – first impressions matter.
Human eyes are trained to take visual data and focus on the most prominent features in it. This helps the eye to communicate to the brain, whether the image being processed is signaling some danger or not. Hence, many a time, our entire perspective on an image revolves around the prominent features which we process and remember.
RAM uses the exact same idea. The model starts with cropping the image in different proportions and sizes. With each different proportion, it understands the common centers in the image. Using prominent features in each of these segments, glimpse vectors are created – using the principle of processing an image on the basis of just a glimpse. All the transparent layers that might be covering other objects in the image get flattened, as these glimpse vectors are processed through a glimpse network.
After this, it becomes a process of forecasting the next location in the image that has to be processed. The glimpse vector, as processed through the glimpse network, is passing through a location network that uses back propagation as its proxy for analyzing whether the last processing layer was accurate enough to predict the next location for processing in the image. Incorporating proxy rotating into RAM's methodology could significantly enhance its adaptability, allowing the model to dynamically adjust its focus areas within the image, much like adjusting a lens to capture different angles, thereby improving the precision of identifying and processing key features across various segments.
3. Attention-OCR
Attention-OCR takes a few pages from the processing workflow of CRNN methodology. It divides the image into features that easily lend themselves for processing. Once the features are segmented, they are run through an encoding-decoding process. It uses an RNN encoder to work through the image's encoded features. As that is achieved, it uses a sophisticated visual attention model to decode these and produce the final output. The attention-mechanism used in this model is based on the Seq2Seq2 machine translation model. You can find Attention-OCR as one of the more prominent OCR projects on TensorFlow.
OCR Applications
Now that we have taken a guided tour through the modern OCR engine, it is worthwhile to understand the use-cases for OCR as a reliable technology:
1. Print to Process: It would be nearly impossible to get process-worthy documents out of printed documents that are scanned as images unless there is some deep learning at work. With more sophisticated applications, it has become easier to take printed documents and convert them into a format that can be used by word processors. Now that the printed documents are easily accessible via word processors, they are also ready to be indexed by Google and other search engines.
2. Creating Searchable Databases: This was the primary use-case for the initial research around OCR. Now that converting physical documents and digital images into accurately processed text-files has become more accessible, searchable database creation and management can be entirely automated from data entry to processing to storage. Such databases will be highly valuable for archiving, legal documentation, and even financial transaction processing.
3. Translating Text to Other Languages & Mediums: Once the text has been accurately recognized, real-time translation becomes a linear process. To add to this, the same text can be used with text-to-speech products for helping visually impaired people to interact with textual information.
Docsumo is the plugin tool that can help you automate the whole process of document extraction. Not only this but it also integrates with other software seamlessly. You can count on us for all your document automation processes and can focus on more innovative and productive tasks for your organization.
By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.