
Suggested
An in-depth Guide to Automated Invoice Scanning Software
Automated Invoice Processing, a key back-office task that can lead to a great deal of time & cost savings if automated correctly.
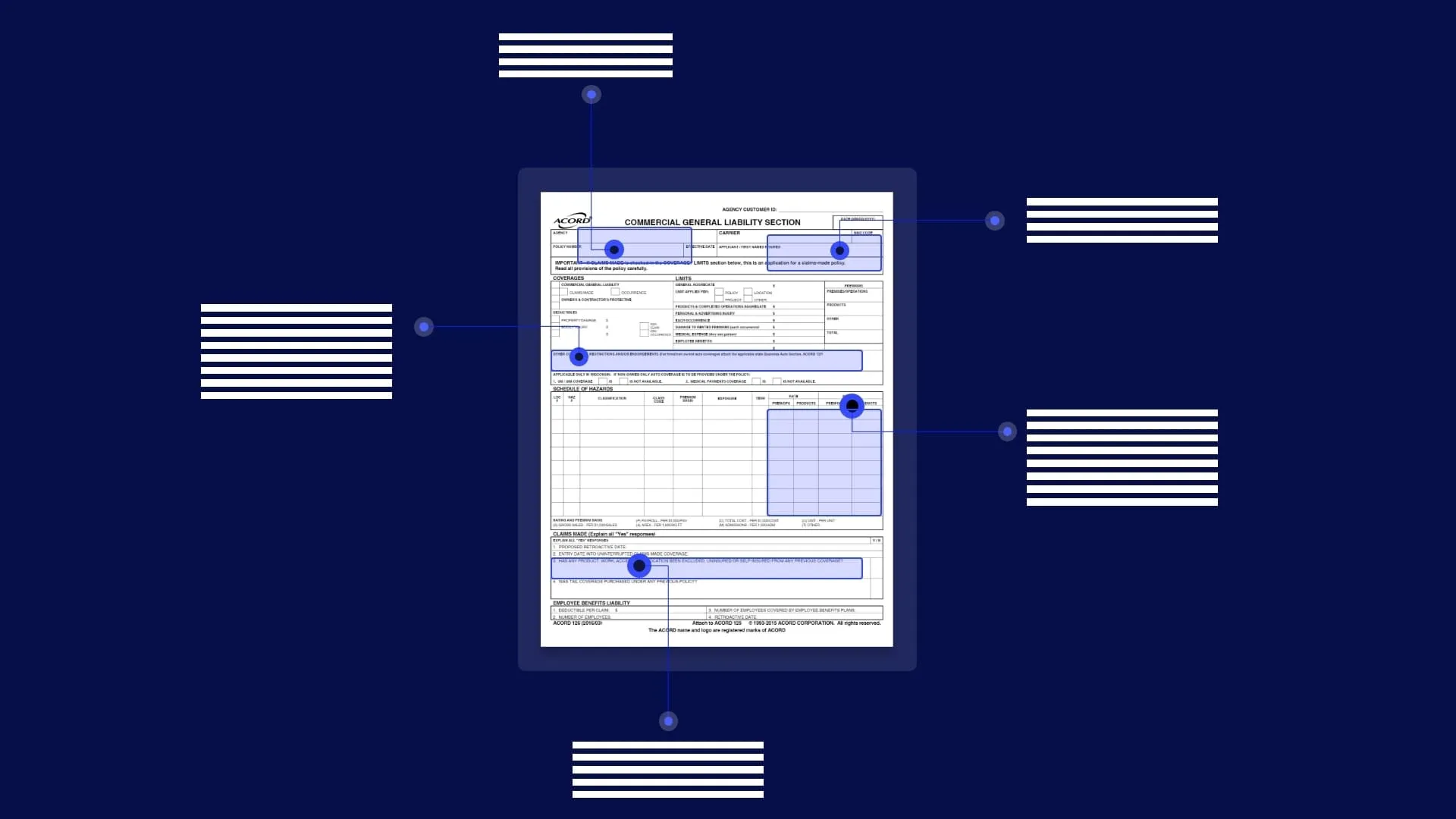
Document annotation refers to the process of identifying fields and associated values in a document and extracting relevant information using a set of criteria. Machine learning algorithms and AI technologies are used to classify data sets in files and extract data without requiring any human intervention. Annotating documents makes it easier to sort through and find specific information without needing to go through entire documents. It also makes it convenient to structure data and showcase it in a presentable format that is widely accepted by other users. Organizations hire dedicated specialists for document annotation but with innovations in document annotation technology, OCR, and RPA, companies no longer need employees to manually look up data in files and focus on more productive tasks instead.
Document annotation involves labeling and organizing data in a way that it delivers key insights and makes it approachable for further analysis. The step before data extraction is what is referred to as data annotation because information cannot be extracted unless it is found first.
A classic real-world example of document annotation would be locating the number of instances of the value ‘city,’ in a novel. With document annotation, you can scan through paragraphs of texts and find the frequency of that field. Likewise, you can apply document annotation technology to locate key information in payslips, invoices, purchase orders, receipts, and other document types.
Document annotation automation software is used by various industry verticals to digitize and streamline business processes. From educational institutions, public share trading companies, logistics, and supply chain operations, the importance of document annotation cannot be ignored when it comes to processing critical information.
Document annotation helps verify and validate information by finding and assigning the appropriate key-value pairs and line-items in a document. It is used for mapping out data for authenticating details and cross-referencing past models. Successful annotation is needed so that organizations can run their business operations efficiently without suffering from any delays or downtimes due to erroneous data interpretation.
The following are some of the best practices to use when annotating documents:-
Consistent annotation is more important than correct annotation in 90% cases. Train APIs with datasets and enable them to recognize file structures by manually guiding them for the first few instances. AI technology and smart machine learning algorithms take over the process once you’ve helped it identify key information in documents.
Your extraction schema should be properly set up before you start annotating documents. Make adjustments to key value pairs and ensure that all fields have been assigned the appropriate data types before you begin to annotate. Create sections for different parts of the document and make sure your key value pairs are ordered correctly.
You can use tables during data annotation to make it convenient for organizing information. Set up rows and columns for making lists and use tables to make a summary of data. There are different annotated examples you can find under Docsumo’s APIs & Services modules to get an idea of how to go about this. Every API model is different and each one uses tables in their own unique ways.
When dealing with large quantities of datasets, it is important to involve a number of people in the data mapping and annotation process. Users with more experience in annotating documents can provide feedback to less experienced ones and improve projects.
Request your peers for a manual review after you’ve done your first data annotation. This can help you refine the process and make automated document annotation seamless. You don’t have to read all the details, just the ones which are important.
Once you have trained the API to annotate your documents, you can save the changes and finish creating API modules. The document annotation process involves assigning key value pairs and this is the critical part. Your API models will take over and automatically reduce processing times when you’ve set up this process right.
Focus on the quality of your annotations instead of trying to bulk process documents to make automation smoother down the line. You can apply the API to annotate documents in multiple batches once it accurately annotates your initial samples.
Docsumo uses intelligent OCR and AI to annotate and extract data from documents automatically for users and removes the need for manual data extraction. The software can find and extract data from semi-structured documents as well.
To experience this firsthand, sign up for a free demo with Docsumo and watch how we make your document annotation experience hassle-free!
Save 100+ hours a month by automating all your low-impact tasks so that your team can prioritize faster and accurate business decisions, every time.
Get Your Free Trial Today
.webp)
.webp)
.webp)
.webp)