.svg)
.svg)
The Only OCR Software that Automates Document Workflows in Seconds
Move beyond manual data entry errors to drive 10x faster document processing. Discover the top optical character recognition (OCR) software to consider in 2025.
Get StartedTrusted by 10,000+ data-driven businesses




.avif)
Take a Spin Around Our OCR Platform
Businesses Do Extraordinary Things With Docsumo
.svg)
$100 Million
Saved in processing costs
.svg)
3.4 Million
Work hours saved
.svg)
20 Million
Documents processed
.svg)
95%+
Straight-through processing achieved
The Best OCR Software of 2025 Ranked
Docsumo
Docsumo is an AI-powered OCR software tailored for technology teams looking to get clean data tables from their documents.
Key features -
- AI-powered data extraction for complex documents (invoices, bank statements, contracts).
- Multiple input methods: emails, APIs, cloud drives, local uploads.
- Customizable validation rules for accurate data and seamless integration.
- Pre-trained AI models with options for custom training on specific datasets.
- Intuitive, user-friendly interface for reduced manual efforts and errors.
- Streamlines document workflows, improves accuracy and cuts processing time.
Things to consider -
According to user reviews, no significant limitations have been reported regarding Docsumo's performance.
Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents. Unlike basic OCR, it can identify, interpret, and retrieve specific data from documents.
Key features -
- Automatically detects and extracts printed and handwritten text from documents.
- Identifies and extracts key-value pairs, preserving context-like fields and their values.
- Extracts table data while maintaining the structure of rows and columns.
- Recognizes layout elements like paragraphs, titles, and headers for better document understanding.
- Allows query-based extraction, retrieving specific data using natural language queries.
Things to consider -
- Accuracy for handwritten documents can be low, requiring manual intervention.
- Service can be expensive, especially for large-scale document processing.
- Limited language support is available.
Google Document AI
Google Document AI extracts structured data from documents, allowing for efficient analysis, search, and storage. The Document AI suite includes pre-trained models for data extraction, the Document AI Workbench for creating custom models or enhancing existing ones, and the Document AI Warehouse for searching and storing documents.
Key features -
- Transforms scanned images and PDFs into searchable, editable text with OCR.
- Extracts key-value pairs and table data from structured forms.
- Categorizes documents using machine learning for efficient organization.
Things to consider -
- Some documentation is outdated or ambiguous, with limited code examples for various use cases.
- Instructions for training models are unclear, especially for non-technical users.
- Multilingual support is minimal.
- MultilinData extraction from PDFs can sometimes be inaccurate, requiring manual retraining.gual support is minimal.
ABBYY FlexiCapture
ABBYY FlexiCapture is a highly advanced OCR tool praised for its efficiency in digitizing, editing, and managing PDFs, Word documents, and scanned files. It offers a graphical interface that allows users to scan documents, import them, and apply OCR to them.
Key features -
- Utilizes AI-powered OCR for highly accurate text recognition.
- Supports a wide range of document formats.
- Comprehensive tools for editing and managing PDFs.
Things to consider -
- Some advanced features may have a steeper learning curve for users.
- The pricing can be higher compared to more basic OCR solutions.
Rossum
Rossum is an AI-powered document processing platform designed to automate data extraction for accounts payable, customs, order management, and quality assurance use cases. It offers a customizable solution with high accuracy and minimal setup, which is ideal for businesses seeking to streamline transactional workflows.
Key features -
- AI-powered document processing with a focus on invoices and purchase orders.
- Customizable AI models with minimal training required.
- Human-in-the-loop capabilities for validation and review.
- Seamless integration with ERP systems like SAP and Oracle.
Things to consider -
- Primarily focused on transactional documents; less flexibility for other types.
- Requires some setup and training for custom workflows.
Nanonets
Nanonets provides a no-code AI platform for document automation, featuring pre-trained models for limited document types. It aims to offer scalable solutions for businesses looking to enhance document processing with minimal customization.
Key features -
- Customizable no-code platform for training AI models.
- Fast deployment of the solution.
- Integrates easily with ERP systems like QuickBooks and Salesforce.
Things to consider -
- Limited advanced AI and ML features compared to more robust platforms like Docsumo.
- Some users report the need for further model customization for unique document types.
The Best OCR Software of 2025 Ranked

Docsumo
Docsumo is an AI-powered OCR software tailored for technology teams looking to get clean data tables from their documents.
Key features -
- AI-powered data extraction for complex documents (invoices, bank statements, contracts).
- Multiple input methods: emails, APIs, cloud drives, local uploads.
- Customizable validation rules for accurate data and seamless integration.
- Pre-trained AI models with options for custom training on specific datasets.
- Intuitive, user-friendly interface for reduced manual efforts and errors.
- Streamlines document workflows, improves accuracy and cuts processing time.
Things to consider -
According to user reviews, no significant limitations have been reported regarding Docsumo's performance.
Pricing -
Dosumo’s pricing model is divided into Free, Growth, and Enterprise plans. The Free plan offers a free trial, which includes 100 pages per month. The price per page for the Growth plan starts at $0.3.
Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, layout elements, and data from scanned documents. Unlike basic OCR, it can identify, interpret, and retrieve specific data from documents.
Key features -
- Automatically detects and extracts printed and handwritten text from documents.
- Identifies and extracts key-value pairs, preserving context-like fields and their values.
- Extracts table data while maintaining the structure of rows and columns.
- Recognizes layout elements like paragraphs, titles, and headers for better document understanding.
- Allows query-based extraction, retrieving specific data using natural language queries.
Things to consider -
- Accuracy for handwritten documents can be low, requiring manual intervention.
- Service can be expensive, especially for large-scale document processing.
- Limited language support is available.
Pricing -
Amazon Textract offers a pay-as-you-go pricing model, with rates varying based on the specific API used and the number of pages processed. The basic plan for 1,000 pages begins from $1.50 per page.
Google Document AI
Google Document AI extracts structured data from documents, allowing for efficient analysis, search, and storage. The Document AI suite includes pre-trained models for data extraction, the Document AI Workbench for creating custom models or enhancing existing ones, and the Document AI Warehouse for searching and storing documents.
Key features -
- Transforms scanned images and PDFs into searchable, editable text with OCR.
- Extracts key-value pairs and table data from structured forms.
- Categorizes documents using machine learning for efficient organization.
Things to consider -
- Some documentation is outdated or ambiguous, with limited code examples for various use cases.
- Instructions for training models are unclear, especially for non-technical users.
- Multilingual support is minimal.
- MultilinData extraction from PDFs can sometimes be inaccurate, requiring manual retraining.gual support is minimal.
Pricing -
Google Doc AI offers a pay-as-you-go pricing model. Basic OCR starts at $1.50 per 1,000 pages, with additional costs for more advanced features that come with the different processors.
ABBYY FlexiCapture
ABBYY FlexiCapture is a highly advanced OCR tool praised for its efficiency in digitizing, editing, and managing PDFs, Word documents, and scanned files. It offers a graphical interface that allows users to scan documents, import them, and apply OCR to them.
Key features -
- Utilizes AI-powered OCR for highly accurate text recognition.
- Supports a wide range of document formats.
- Comprehensive tools for editing and managing PDFs.
Things to consider -
- Some advanced features may have a steeper learning curve for users.
- The pricing can be higher compared to more basic OCR solutions.
Pricing -
ABBYY offers two different plans for the FlexiCapture solution, catering to businesses and individuals. The pricing for their Individual plan begins at $34.50/year for Mac devices and $49.50/year for Windows users.
Rossum
Rossum is an AI-powered document processing platform designed to automate data extraction for accounts payable, customs, order management, and quality assurance use cases. It offers a customizable solution with high accuracy and minimal setup, which is ideal for businesses seeking to streamline transactional workflows.
Key features -
- AI-powered document processing with a focus on invoices and purchase orders.
- Customizable AI models with minimal training required.
- Human-in-the-loop capabilities for validation and review.
- Seamless integration with ERP systems like SAP and Oracle.
Things to consider -
- Primarily focused on transactional documents; less flexibility for other types.
- Requires some setup and training for custom workflows.
Pricing -
Rossum segments its custom pricing model into four categories based on volume and specific use cases - Starter, Business, Enterprise, and Ultimate. The Starter plan starts at $1,500 per month.
Nanonets
Nanonets provides a no-code AI platform for document automation, featuring pre-trained models for 300+ document types. It aims to offer scalable solutions for businesses looking to enhance document processing with minimal customization.
Key features -
- Customizable no-code platform for training AI models.
- Fast deployment of the solution.
- Integrates easily with ERP systems like QuickBooks and Salesforce.
Things to consider -
- Limited advanced AI and ML features compared to more robust platforms like Docsumo.
- Some users report the need for further model customization for unique document types.
Pricing -
Nanonets has a pay-as-you-go pricing based on usage and offers three plans - Starter, Pro, and Enterprise. The price per page for the Starter plan begins at $0.3 based on the complexity of the document.
Four Ways Docsumo OCR Automates the Document Processing Workflow
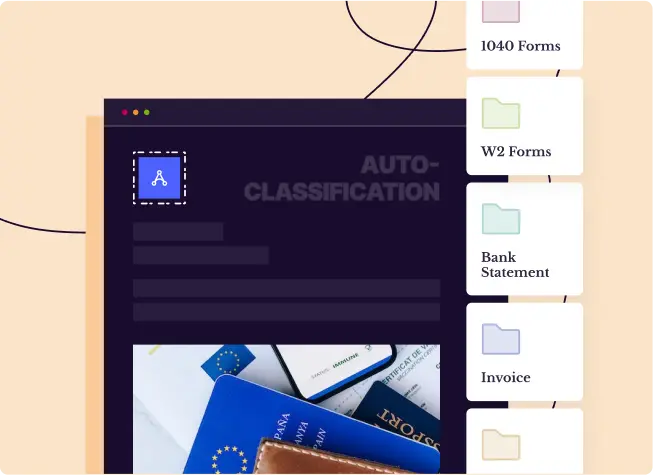
Ingest, classify and pre-process any document
- Send documents via emails, API, cloud drive or local machine
- PDF, PNG, JPG, Excel, TIFF, .TXT, Emails - Bring them all into Docsumo using our powerful APIs
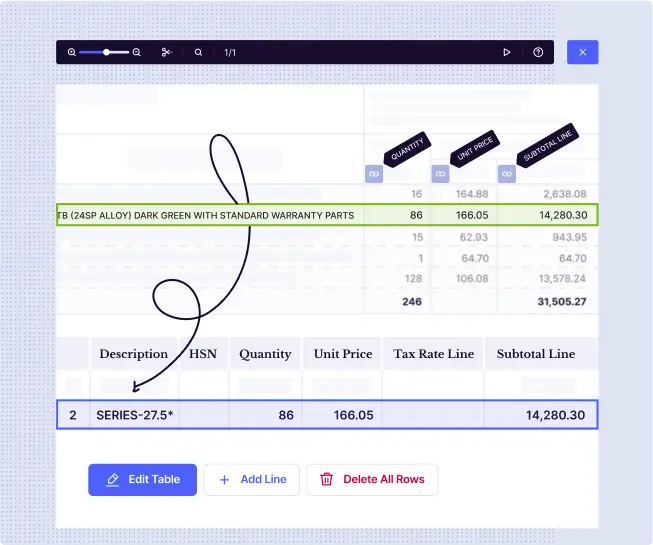
Accurately capture key values & tables from unstructured documents
- Let’s accept it - documents like invoices, banks statements, contracts, rent rolls, bill of lading, energy/utility bills, ACORD forms, IRS Form 1040 are unstructured
- Docsumo’s intelligent AI enables you to extract and easily review only the fields you need from complex documents
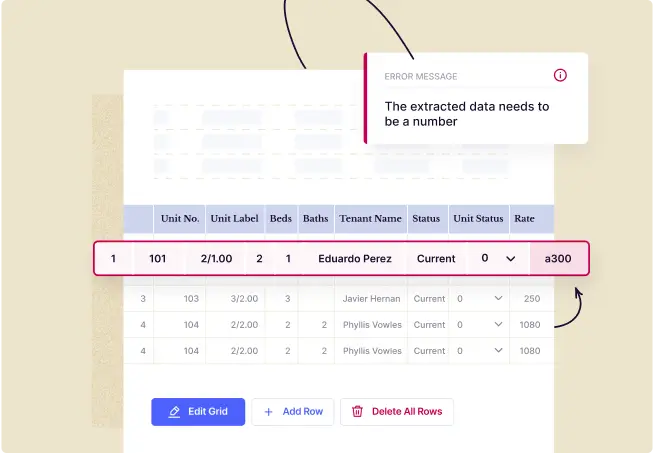
Reduce errors by validating data within a document
- Create excel-like rules/formulae to validate extracted data within your document, across documents or against a database
- Categorize table line items based on descriptions to derive key metrics required for decisioning
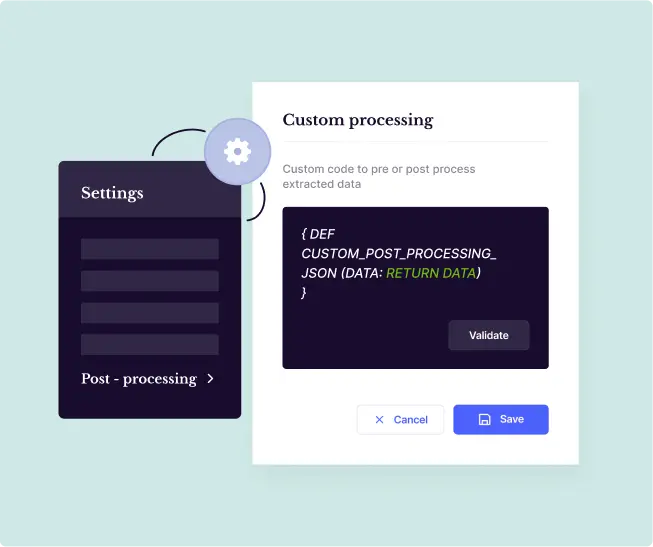
Post-process and directly integrate data with downstream systems
- No matter the industry - Insurance, Underwriting, Financial Services, Lending, Logistics - we’ve got APIs ready for you
- All that you’ve got to do is integrate the data fields in your systems with our APIs. And, you’re ready to analyze the data and make intelligent automated decisions
11-Step Checklist to Consider When Choosing an OCR Software
Five Modern OCR Software Features to Look For
AI and Machine Learning (ML)
- AI and ML technologies enable OCR to continually adapt and improve accuracy levels by learning from past data inputs to recognize patterns.
- This comes in handy when dealing with unstructured data, such as invoices or utility bills, whose format and processing complexity vary.
Table data extraction
- Table data extraction allows most modern OCR tools to process structured data from long-drawn, unstructured tables accurately.
- This feature helps capture critical values across documents like large financial statements or product inventories, where the tables contain detailed breakdowns or multiple line items.
Handwritten Text Recognition (HTR)
- HTR allows OCR software to scan handwritten notes, forms, and historical records, converting them into digital formats without losing accuracy.
- This ability makes it an essential tool for industries like healthcare and legal services, where handwritten documents are still prevalent.
Support for complex layouts
- OCR software has become adept at handling documents with complex layouts, including multi-column formats, embedded images, graphs, and tables.
- This feature is crucial for documents such as newspapers, research papers, and technical reports, where data is presented in various forms, and the layout might be different.
Natural Language Processing (NLP)
- NLP enables OCR software to recognize text and understand its context by recognizing entities, keywords, and phrases.
- This is critical for improving searchability and discovering insights across documents.
Industry-specific Use Cases of Docsumo OCR
.webp)

.webp)




.webp)



.webp)

.webp)




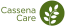

Financial Services
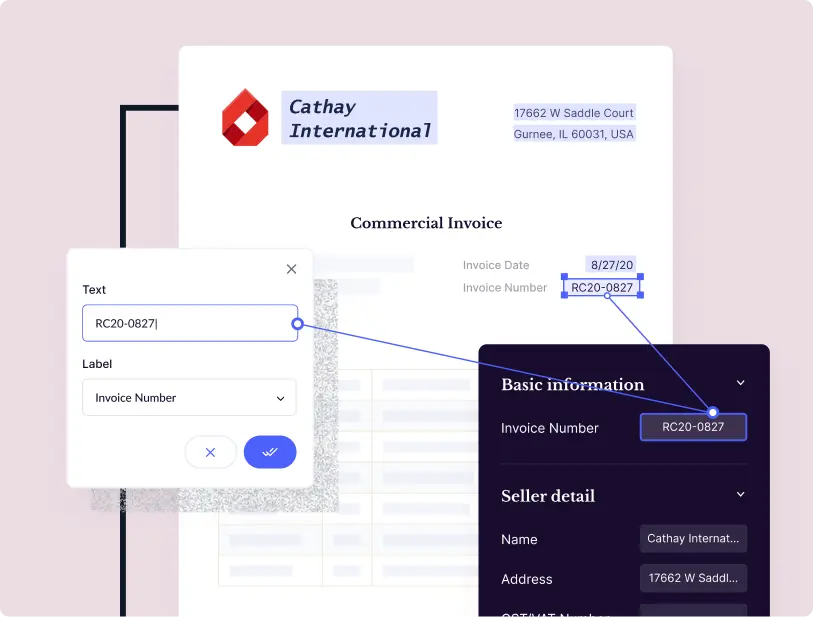
- Docsumo's AI-powered OCR can parse through varied fonts, unstructured templates, and diverse document formats like PDFs or JPEGs. The documents shared by creditors can be ingested into the software via robust API, and the Docsumo pre-processing engine takes over to help you categorize line items, calculate ratios, and validate totals in financial statements.
- Docsumo allows financial operations teams to automate debt settlement letter processing, saving over 2,100 work-hours monthly.
Find out how.
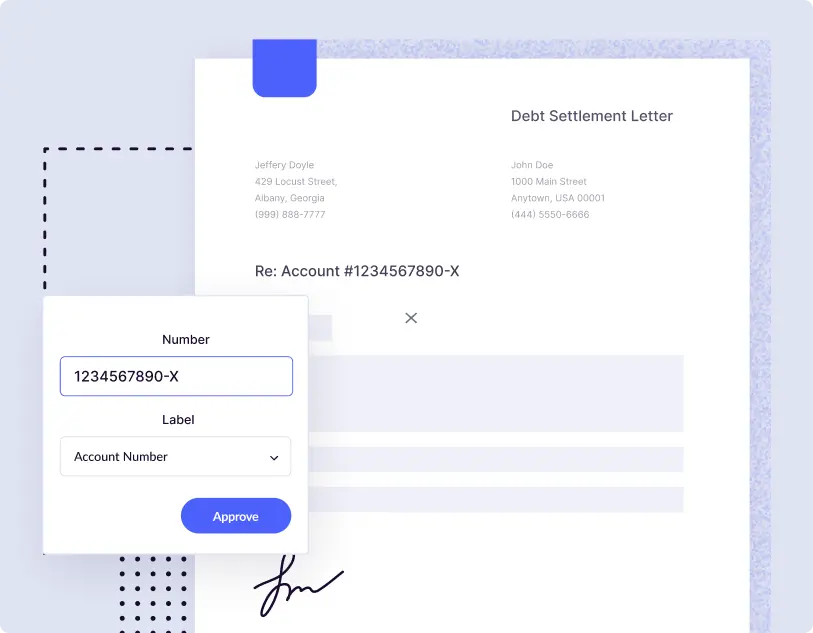
Real Estate
- Docsumo's AI-powered OCR engine automatically ingests tenant documents like rent rolls, ACORD forms and insurance certificates and uses the pre-procesor to convert scanned data into machine-readable information. This allows operations team to quickly validate and approve the processed data, post which the data is pushed to their LOS to enable faster lending decisions.
- Real estate companies leverage Docsumo OCR to drive 96% faster ACORD form processing with over 99% accuracy. Read how.
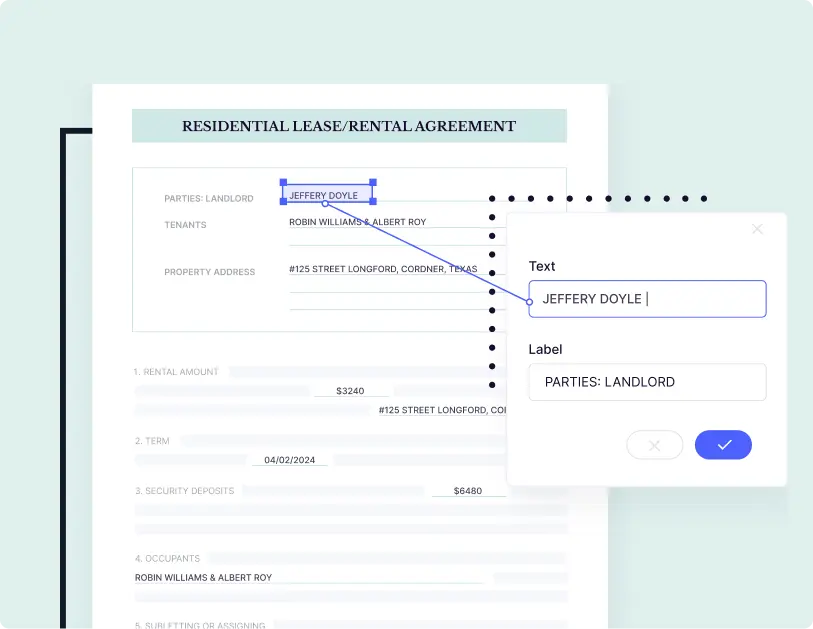
Insurance
- Docsumo's OCR software helps operations teams in insurance companies to extract granular data, such as income information and exclusions. The software allows them to validate the processed data with excel-like formulae and perform advanced calculations before sending it to Guidewire, Majesco, or Duck Creek for faster claims-related decisions.
- With Docsumo, insurance teams can automate the processing of over 10,000 flood certificates and insurance claims with 400 work-hours saved monthly. Find out how.
Logistics
- AI-powered OCR software helps logistics operations teams to close outstanding accounts payable with accurate data capture for efficient pre- and post-transportation management. Docsumo OCR goes a step further by processing images and scanned copies of BOLs and invoices shared by shipping centres or truck drivers and integrating them to their TMS or WMS.
- Docsumo helps logistics companies accelerate the processing of bills of lading and invoices, while saving while saving the accounting team over 2,500 work-hours monthly. Read how.
Healthcare
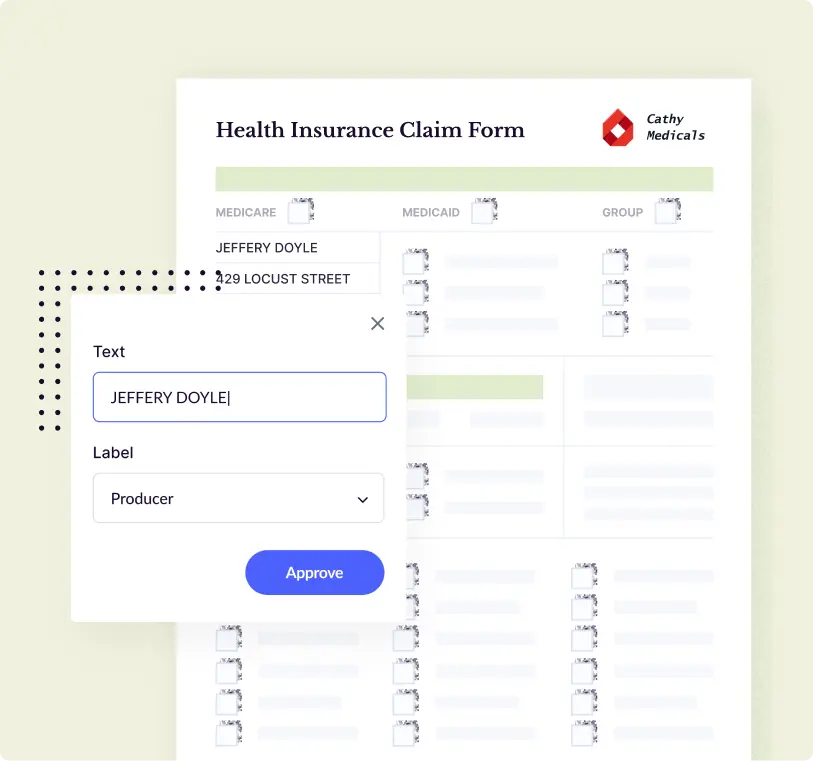
- Healthcare companies often deal with thousands of medical invoices, prescriptions and statements that need digitization. OCR software like Docsumo can simplify manual data extraction complexities and reduce processing time from hours to a few seconds with high accuracy.
- Docsumo OCR helps healthcare companies onboard patients 2x faster by processing 100k+ medicaid applications automatically with over 99% accuracy. Read how.
Energy and Utilities
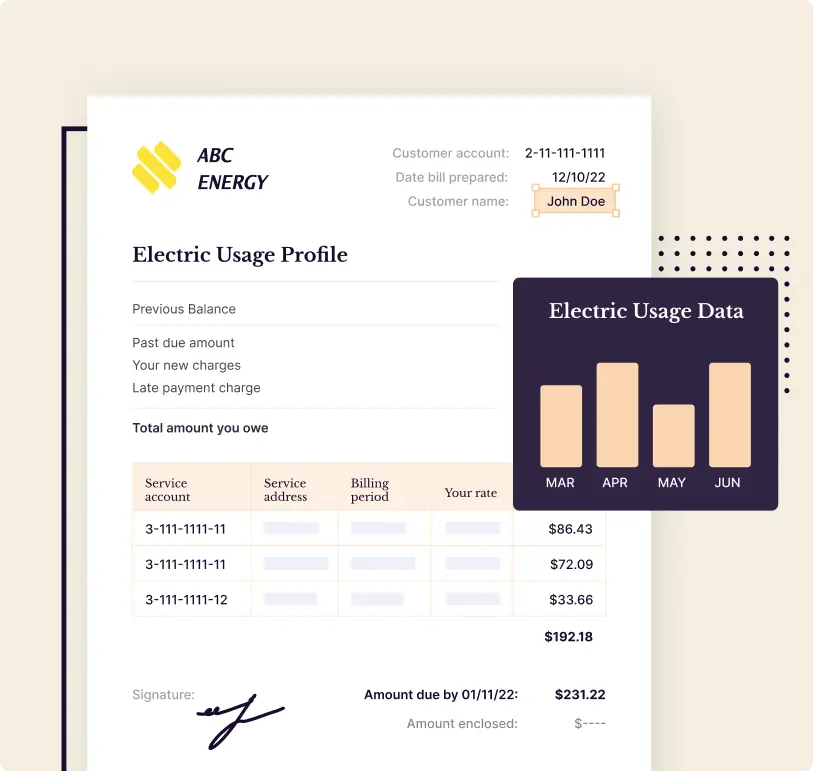
- OCR software can automate accounts receivable, revenue reconciliation and fuel or emission emission management while significantly reducing processing team. Data entry operators in energy and utilities companies observe seamless ingestion of utility bills that get automatically processed with pre-trained models. Operators can also export the data to their downstream systems in CSV or other formats for further processing.
- Energy management companies leverage Docsumo OCR to automate 97% of their utility bill processing workflow to ensure over $2,500 saved in processing costs monthly. Find how.
Software
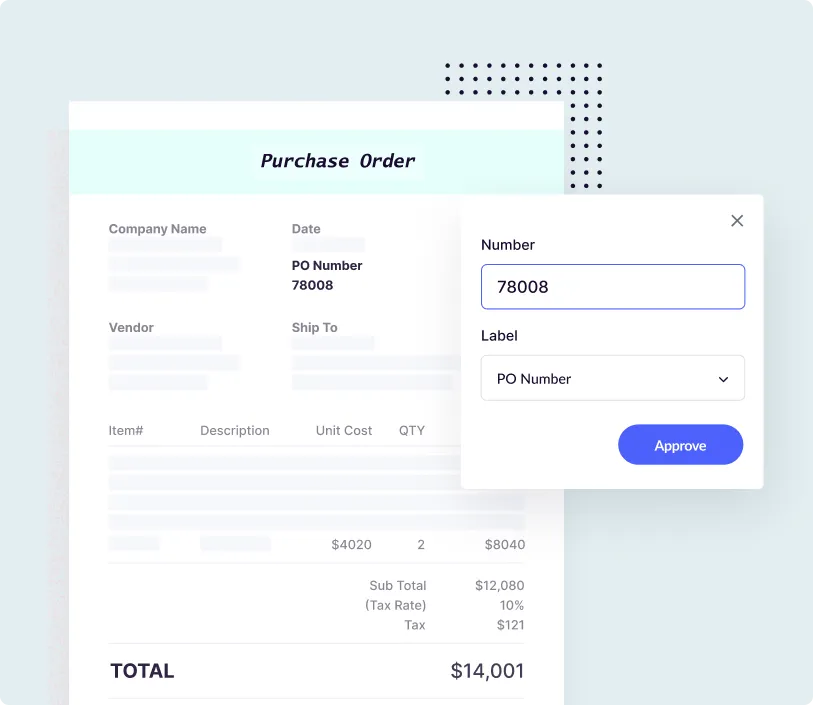
- AI-led OCR can solve for manual data extraction and entry across varied documents, images and scanned files for software companies without the need for extensive IT support. This enables software teams prioritize code documentation, risk management and compliance over clerical processing tasks.
- IT and operations teams across software companies leverage Docsumo OCR to drive 10x faster unstructured document processing for their clients with over 99% accracy. Find out how.
