8 Best Document Fraud Detection Systems to Safeguard Your Business
In this blog, we discuss the essential role of document fraud detection systems in safeguarding your business. Explore the top benefits, in-depth insights, and leading solutions for 2024.


Advancements in AI and deep fakes and the availability of sophisticated online tools led to a massive increase in document fraud. Fraudsters target document data and biometric elements, and rule-based fraud detection systems may not be sufficient as fraudsters innovate.
Frauds can cause reputational damage, customer loss, direct financial loss, and regulatory penalties. Onfido’s 2024 identity fraud report claims that:
- Fraudsters targeted gambling, professional, financial, and healthcare businesses the most in 2023
- The most commonly tampered documents are national IDs (46.8%), passports (23.7%), driving licenses (17.5%), and tax reports (6.0%)
Increasing threats necessitate a robust defense, so 71% of businesses have increased spending on advanced fraud detection technologies. A strategic approach of blending tools and humans is reliable for fraud document detection, ensuring security, and maintaining the business reputation.
This article discusses document fraud, its types, red flags, benefits of implementing a document fraud detection system, and critical features to look for in a tool. We also review the top fraud detection solutions in the market, including their features, limitations, pricing, and ratings, to help you choose the best one.
What is a Document Fraud Detection System?
A document fraud detection system is software designed to analyze documents and identify fraudulent activities. These solutions are part of fraud prevention strategies across industries, including healthcare, gaming, cryptocurrency, financial, e-commerce, insurance, and government services.
Fraud document detection solutions automatically analyze large volumes of identity and transactional data in documents to distinguish legitimate customers from fraudsters. This automated detection and human review and feedback accurately detects business fraud.
Types of Document Fraud
The document fraud industry is estimated to be valued at 3.2 trillion pounds, and it's one of the largest targets for fraudsters.
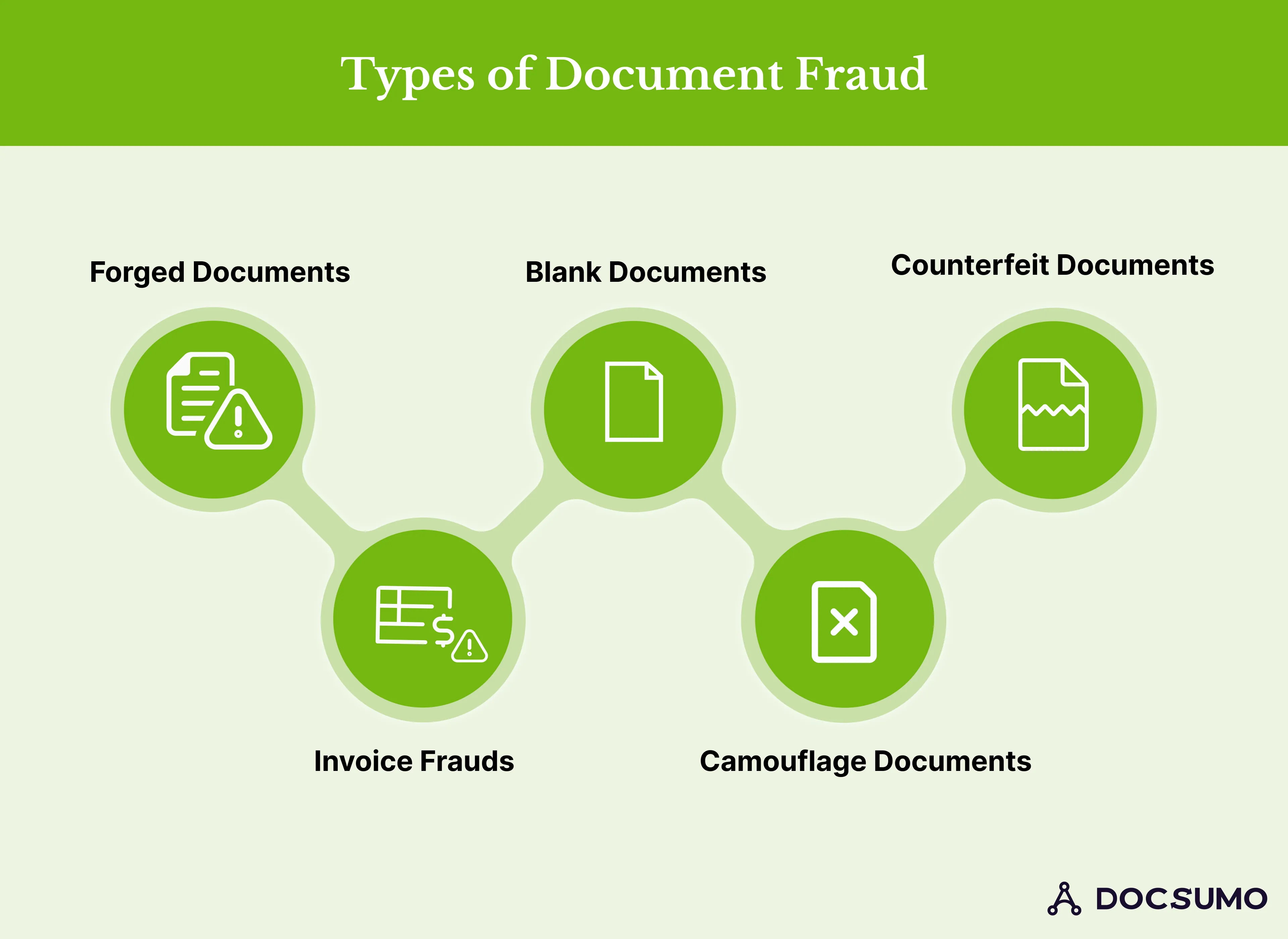
The most common types of document fraud are:
1. Forged documents
Forged documents are files whose details have been tampered with. Fraudsters can completely change information or partially alter it. Examples of forgeries in documents include adding timestamps or watermarks to files, inserting and removing pages, and digitally altering signatures. The integrity of documents is affected when they are forged.
2. Invoice fraud
This is when an employee impersonates a vendor and generates a false invoice. This is sent to the company who disburses funds directly to user accounts
3. Blank documents
Blank documents can be used to insert falsified information leaked from the manufacturing supply chain. Since they are empty and need to be verified for security, blank fields can be tampered with.
4. Camouflage Documents:
These are fake identities created by fraudsters representing themselves as government officials or authorized entities. This rare type of fraud can sometimes slip through the cracks if left unchecked.
5. Counterfeit Documents:
These are unauthorized reproductions of official documents. The perpetrator’ can use these reproduced files to access additional confidential information. An example of counterfeit document fraud is using a victim’s driving license to learn about their social security number and bank account details.
Red Flags in Document Checks
Document fraud detection technology has evolved at unprecedented rates with the advent of Artificial Intelligence and Intelligent Document Processing (IDP).
Businesses seek automated software that saves hours sorting through data and retrieving file records. Here are a few red flags to watch out for when reviewing the information presented in structured and unstructured documents:
1. Metadata Analysis: PDF files that show structural inconsistencies and have suspicious zones that are too different from the original parts of documents
2. Financial transactions: Bank statements that cross-check monthly income with average balance and key financial APIs for verifying customer details
3. OCR and Barcode Data: Content obtained through OCR reading, biometric identification, and barcode scanning can be validated against official data repositories for verification and validation purposes
4. Duplicate Reports: These schemes involve using duplicate invoices or making double payments. Another red flag is when an employee raises a refund after purchasing an item using the company’s funds and transfers the money directly to their account
5. Other Variables: Reviewing metrics like total decline rates, cost per analysis, checkout abandonment rates, invoice numbers, and key fraud APIs
Ultimately, there is an element of human error involved that is why no document processing software is 100% accurate.
95 to 98% accuracy is ideal - The accuracy level of Document Fraud Detection processes is not 100% perfect, but an accuracy of 95 to 98% is considered the ideal industry benchmark.
How to Detect Fraudulent Documents?
There are two ways businesses can detect fraudulent documents: manual verification and automated fraud detection solutions.
Some of the obvious signs fraud analysts can look for in tampered documents are:
- Missing or altered numbers
- Data entry errors such as spelling mistakes, incorrect dates
- Inconsistencies in font style, size and formatting, and text alignment
- Low-resolution logos and low-quality documents
Though manual fraud detection is possible, less than 10% of document fraud is visible to the human eye.
On the other hand, document fraud detection solutions efficiently spot fraud elements and unusual patterns in documents in real-time. The platform's AI/ML algorithms and Optical Character Recognition (OCR) technologies make it possible to detect fraudulent manipulations.
Here's how it works:
- Data matching: Extracts relevant identity and financial data from documents and validates them with available databases to identify inconsistencies and manipulated entries.
- Image analysis: Locates images in the documents to analyze metadata, resolution, lighting, and shadows and identify if they are edited using Adobe Photoshop.
- Grayscale analysis: The grayscale analysis method analyzes the pixel value distribution across the document to detect changes in texts, logos, and signatures.
These advanced techniques ensure that no fraud ever goes undetected, thereby mitigating financial risks for organizations.
Benefits of Implementing a Document Fraud Detection System

1. Enhanced security and protection
By analyzing real-time data, businesses can identify frauds earlier and take proactive measures to identify potential threats on time. Advanced security measures and tamper-proof technologies help protect customer data against cyber attacks.
2. Compliance with regulatory requirements
Businesses operating across various countries should adhere to different compliance policies, such as GDPR, CCPA, AML, KYB, and KYC. A document fraud detection system accurately verifies a user's identity, reducing fraud and ensuring compliance with evolving regulatory standards.
3. Reduction in financial losses
According to BioCatch’s 2024 AI, Fraud, and Financial Crime Survey, 58% of respondents spent between USD 5 million and USD 25 million in operational costs in 2023 on investigating, combatting, or rectifying the consequences of financial crime.
Document fraud detection systems reduce financial losses and prevent regulatory fines by accurately detecting fraud. For instance, lending businesses can verify a borrower's identity and analyze if the transactions are legitimate or made up.
Upon accurate analysis, companies can avoid sanctioning loans to fraudsters at this stage and mitigate associated risks.
4. Improved operational efficiency
A document fraud detection platform automatically classifies documents, extracts identity data, validates with databases, and decodes repetitive patterns. Such automated solutions reduce the reliance on human resources, allowing employees to focus on high-value tasks like devising fraud detection strategies.
5. Improved trust and reputation
Customers and stakeholders engage only with businesses that use effective fraud detection strategies. Additionally, data security measures that protect customer data against threats and phishing attacks are important to gain and sustain their trust.
A fraud document detection platform helps businesses achieve these with machine learning algorithms and robust security features.
How to Choose The Best Document Fraud Detection System
Some critical factors to consider when selecting a document fraud detection system are:
a. Accuracy and reliability
Choose a platform that provides a 95-99% accuracy rate to avoid manual reviews and improve efficiency. A low false-positive rate ensures a positive customer experience and increased sales.
b. Integration with existing infrastructure
The document fraud detection solution should seamlessly integrate with existing infrastructure, legacy systems, DMS, CRMs, ERPs, and accounting software solutions to facilitate real-time data analysis and a unified view of risks across different systems. Robust integration capabilities and APIs help prevent fraudulent activities on time.
c. Scalability
A scalable system that easily handles growing volumes of documents can be a vital asset for organizations. Mainly, the platform should maintain consistency, quick loading and processing time, and accuracy while scanning documents at scale.
d. Real-time detection and response capabilities
Real-time fraud detection helps businesses identify irregularities early, supporting fraud prevention efforts and avoiding potential risks. A platform that automatically routes documents and alerts the relevant personnel helps expedite review and decision-making.
e. Cost-effectiveness and return on investment (ROI)
Consider the following costs associated with a document fraud detection system:
- Operational costs such as software licenses, hardware, maintenance, and employees salaries
- Training costs to equip employees on using AI technologies for fraud detection
- Recurring monthly costs for processing documents and detecting fraud
After evaluating the pricing of various solutions, calculate the return on investment in terms of efficiency, accuracy, and cost reduction to choose the one that best fits the budget.
Top 8 Document Fraud Detection Systems in 2024
Now let's evaluate the top 8 document fraud detection systems in 2024:
1. Docsumo

Docsumo leverages machine learning and deep learning algorithms to help enterprises analyze suspicious patterns and trends in documents and detect fraud.
Firstly, it detects missing pages and altered formatting and presentation of documents. Then it captures relevant data from documents and validates them against company databases to identify discrepancies and inconsistencies.
The platform also automatically reconciles the transactions in bank statements and tax reports to ensure authenticity and identify incorrect data.
Key features
- Pre-trained API models extract relevant identity and financial data
- Performs two/three-way matching and evaluates data against multiple databases (internal and government) to detect fraud
- Alerts relevant employees for further review and analysis in cases of suspicious patterns
- Integrates with CRMs, ERPs, and accounting software solutions
Limitations
- Lacks features related to biometric verification
Pricing
- Growth: $500+ per month
- Business: Custom pricing
- Enterprise: Custom pricing
Ratings
- G2: 4.7/5
- Capterra: 4.6/5
2. DocVerify
DocVerify’s electronic notary platform allows the notary public to verify the authenticity of document signatures. Individuals and businesses can directly approach the notary professionals on the platform to get documents notarized for them.
It is a single platform for both parties, streamlining workflows and saving businesses time.
Key features
- Allows notarizing documents and stores notary journal entries
- Robust security features offer the highest level of security for documents stored
Limitations
- Limit on file size of documents that can be uploaded for verification.
- Searching and locating documents inside the platform is tricky.
Pricing
- Business E-sign: $30 per license per month
- Enterprise: $75 per license per month
- Enterprise Group: Custom pricing
Ratings
- G2: 4.1/5
- Capterra: 4.5/5
3. Mitek Systems

Mitek systems maximize business onboarding success by verifying customers and detecting document fraud in real time. Customize settings, configure workflows, modify rules without complex coding changes and start using the solution in hours.
Check Fraud Defender in Mitek systems helps financial institutions analyze more than 20 distinct check attributes with their consortium data to create a truth database and accurately detect fraud.
Key features
- Verifies ID documents, including MRZ and NFC data, and matches them with multiple databases to spot fraud
- Captures the user's selfie and image in documents to perform automatic biometric verification
- Integrates with existing infrastructure such as scanning devices, dedicated kiosks, or BYOD implementations
Limitations
- Detection of high-quality fake IDs is not possible.
- Doesn't support many types of documents.
Pricing
- Custom pricing
Ratings
- G2: 4.5/5 (15+ reviews)
4. Jumio

Jumio is an AI-driven identity verification platform that provides 360-degree insights, tools, and analytics to verify identities, detect deep fakes, and reduce fraud. Build risk-based workflows that meet industry needs and ensure compliance with KYC, GDPR, AML, and CCPA.
Jumio's Device Check also detects advanced risks such as GPS emulation, device rooting, VPNs, proxies, and fingerprinting anomalies.
Key features
- Cross-checks the extracted identity data with the jurisdiction that issued the document
- Verifies the name, address, and date of birth with social security numbers
- Runs the user’s phone number against Global Phone Data Consortium to analyze usage patterns, velocity, and phone data attributes
Limitations
- Integration with existing systems is complex and requires software development support.
- Provides false positive or two different results on the same ID.
Pricing
- Custom pricing
Ratings
- G2: 4.1/5 (15+ reviews)
5. ThreatMetrix

ThreatMetrix is an automated digital identity verification platform that helps enterprises detect fraud, protect users, and streamline customer experience. Their machine learning algorithms are trained on billions of proprietary datasets and improved by human feedback, thus ensuring accurate risk assessments and fraud detection.
ThreatMetrix also detects complex fraud risks throughout the customer journey, from new account opening, login, and account management to payment processes.
Key features
- Extracts identity data and evaluates against known digital identity and trend information to assess risks
- AI algorithms assess signals like geolocation, user device interactions, IP address, and behavioral patterns to filter trusted users
- Build custom machine-learning models by combining signals and past outcomes
Limitations
- The platform is not user-friendly
Pricing
- Custom pricing
Ratings and reviews
- G2: 4.3/5
- Capterra: 5/5
6. Trulioo

Trulioo is a comprehensive identity verification platform that helps enterprises expand global reach with coverage of 450 global and local data sources and 14000+ document types across 190+ countries.
It primarily helps banking, forex, online trading, payments, remittance, and crypto companies verify identity data and onboard customers quickly without compromising speed, security, and accuracy.
Key features
- Extracts data from document barcodes and machine-readable zones automatically
- Digitizes extracted data using OCR technology
- Runs verification and anti-fraud checks and sends exceptional cases to AI-assisted manual review
Limitations
- Too many false positives for customers with common names.
- Identity verification sometimes results in poor match rates.
Pricing
- Custom pricing
Ratings
- G2: 4.4/5
7. Veriff
Veriff leverages a combination of AI and in-house human verification specialists to help finance, gaming, video gaming, dating, HR management education, and healthcare enterprises effectively verify customers’ identities and detect fraud.
It supports over 11,500 document specimens and 48 unique languages from 230 countries, ensuring quick verification and minimal friction. This AI-powered platform analyzes customers' technological and behavioral indicators, and the best part is that it also verifies facial recognition to detect fraud.
Key features
- Pre-filled forms and automatic document recognition recognize uploaded documents, reducing errors and manual input
- Veriff’s Station uncovers insights and fraud risk signals to facilitate informed decision-making
- Real-time image analysis using liveness models detect spoofing attempts (AI-generated selfies, screen presentations, and masks)
Limitations
- Has integration issues with CRMs.
- Processing speed gets slow during peak usage time.
Pricing
- Essential: $0.80 per verification
- Plus: $1.39 per verification
- Premium: $1.89 per verification
- Enterprise: Custom pricing
Ratings
- G2: 4.1/5
- Capterra: 4.5/5
8. Experian CrossCore
Experian CrossCore provides fraud detection, identity verification, and risk-based authentication services to businesses using a single, cloud-based, state-of-the-art identity verification platform.
It analyzes individuals' and entities' identities to help mitigate losses related to lending and non-lending fraud risks. When necessary, the platform sends a One-Time Passcode (OTP) to the users’ verified phone numbers to confirm their identity.
Key features
- 360-degree view of users' identity data to better assess risks
- Advanced analytics that provides confidence scores in every customer interaction
- Integration with other Experian solutions, partners, and internal systems to enable monitoring from a single platform
Limitations
- Cannot develop a custom model according to the business needs
Pricing
- Custom pricing
How Docsumo Helps You to Detect Fraud in Real-time
Document fraud is happening more so due to the latest advancements in technology. Fraudsters are learning how to manipulate information better and hide changes by using graphics processing and deep fake engineering. Image analysis helps in detecting signs of forgery which often go unnoticed.
For example, Docsumo uses an automated procedure that scans for different fields and elements in a document. Analyzing the date of issue for document numbers, identifying low quality images, and differences in photos between the main document and fake document are ways in which the platform makes distinctions between forgeries and real files.
Optical Character Recognition (OCR) makes it possible to note the dynamics and changes in text elements. Similarly, an advanced image editor will also help in enhancing the clarity and authenticity of visual elements in documents.
Fraud document detection systems map protection elements and cross-references with data reference models from authorized sources to confirm the validity and integrity of key information. If anything looks amiss, the platform raises red flags and alerts users to look into the matter.
Here's a list of the most popular features employed by Docsumo for state of the art document fraud detection:
1. B & W Photos: Black and white photos are copies of original documents. Not all of these are fake but it’s helpful for users to learn when they get duplicate copies. In most cases, images of documents captured from secondary sources are fraudulent
2. Document Cropping: If your document has been cropped and details are cut out, Docsumo will flag and ask you to review those files
3. Scanned Images: If the document has been scanned and is not an original copy, the APIs will capture it using intelligent OCR and AI
4. Photo on Photo: Photo on photo cases refer to taking photos of existing documents from photos which have taken of them before. Docsumo intelligently captures the lighting, angle, and exposure of these photos and makes out using ML Algorithms whether you have a photo-on-photo event going on.
Besides these features, the platform automatically detects the formatting and presentation of official documents.
You can extract relevant KPI-values and create automated workflows for cross-checking the structure of pages. If any pages are missing or if the subtotals in invoices don’t add up with taxes, the API will alert users.
Docsumo also reviews details related to document records using 2-way matching and validates captured information against company databases.
Book a demo with us and see Docsumo in action today!
FAQs
1. How to prevent document fraud?
Preventing document fraud and reducing financial losses is now possible with document fraud detection solutions. However, businesses should invest in the right technologies to maximize fraud detection. Advanced solutions like Docsumo use machine learning and deep learning algorithms to help enterprises automate fraud detection with a 99%+ accuracy rate.
2. What are the Key Performance Indicators (KPIs) that should be measured?
Some crucial KPIs to measure are false positive rates, fraud rates, manual review rates, chargeback rates, and review escalation rates. Measuring these KPIs is critical to understanding the document fraud detection system’s performance, setting benchmarks for improvements, and maximizing fraud detection ROI.

