Automated Document Processing Platforms: The What, Why & How
Learn how automated document processing platforms can extract the right data in seconds. Explore the benefits of intelligent document processing—automation of workflows and extractions of actionable data from images, PDFs, and more.

In a research study by Wakefield, 47% of businesses reported delays in processing vendor orders due to manual data management. Additionally, 41% admitted to incurring late fees due to missing payments in handwritten documents.
An automated document processing platform can redefine these outcomes. It is an efficient assistant that automatically ingests and organizes your raw data to deliver actionable information on demand. Don’t believe it? Read how PayU streamlined data extraction from 7 different types of unstructured data (saving over 9,750+ person-hours monthly!).
In this article, you’ll discover what document processing automation platforms are and how they turn time-consuming, error-prone tasks into valuable insights. Let’s go!
What is an Automated Document Processing Platform?
Automated Document Processing (ADP) platforms are tools that combine Artificial Intelligence (AI) with deep learning to revolutionize how your business handles paperwork—whether physical or digital. From handling large documents to processing diverse content (such as tables, images, or handwritten text), an ADP platform can efficiently read, classify, extract, and even populate data.
Only reviews and sign-offs require human attention. This frees up your team to concentrate on business-critical activities, allowing you to err less, process data faster, and create efficient workflows.
One notable real-world example is Carbon Direct. The New York-based carbon management company automated 97% of its utility bill data capture workflow with Docsumo’s document processing capabilities. Consequently, it could assist its clients in reaching their ESG (environmental, social, and governance) goals twice as fast. This resulted in savings of over $2,500 per month in processing costs.
Automated document processing techniques
The process of converting manual and analog forms of information into digitized format involves different automated document processing technologies such as:
1. Computer vision
Computer vision is a technique that enables machines to "see" by mimicking human eyesight. While initially appearing futuristic, computer vision is a natural extension of artificial intelligence (AI) and deep learning, which are swiftly taking over all different industry types.
Computer vision makes us recognize objects and visual patterns quicker than the naked eye. Computer vision also lessens employee fatigue by reducing rote, repetitive activities from being performed by staff members.
Computer vision-based document processing automation recognizes patterns. Here’s how computer vision-powered document processing helps:
- Automates tasks that would otherwise require human supervision using pictures detected by a camera
- Creates algorithms to recognize patterns from documents
- Recognizes and captures information from images
- Identifies patterns more quickly and accurately than manual labor
2. Zonal OCR
The second generation of optical character recognition (OCR) technology is called zonal or template-based OCR. It is used when certain portions of a document need to be extracted preferentially or "zonally."
In other words, regular OCR extracts all data from documents and converts it into digital format without differentiation based on relevance. This means the data requires further manual processing to extract relevant information from the original document.
Zonal OCR extracts specific fields, such as tables and columns, from scanned documents and stores them in a structured format for further processing.
Here’s how zonal OCR works:
- It can identify the structure of a document through APIs
- OCR software then splits into zones corresponding to specific fields
- The zones are extracted as specified in the template
- Zonal OCR can be trained to ignore graphic elements that can be ignored to reduce the amount of information that needs to be parsed to extract specific data
3. Intelligent document processing (IDP)
Intelligent document processing (IDP) is automated data capture from multiple documents and data sources and organization for further processing. It deals with the complexities of processing huge volumes of data accurately and within seconds.
The typical IDP workflow involves:
- Using computer vision algorithms to recognize document layouts from scanned images and files in paper-based and digital formats.
- NLP technology recognizes characters, symbols, and numbers from tables, paragraphs, and unstructured text in documents.
- Using OCR, entity recognition, sentiment analysis, and feature-based tagging, it reads information and inputs it into data management or content management systems with more than 99% accuracy.
What are the Benefits of Automated Document Processing Platforms?
There are many advantages to having an ADP platform for your business. Well-rounded document processing automation helps you:
1. Extract key data insights
Streamline your document processing with a solution that extracts meaningful information from unstructured content for faster and smarter decision-making.
2. Process all document types
With the right ADP solution, you can extract content from digital files or physical paperwork, including purchase orders, lease agreements, delivery receipts, etc.
3. Boost workflow efficiency
Optimize your workflows and increase productivity with advanced automation and data organization.
4. Reduce costs and risks
Achieve predictable performance, improved compliance, and minimal implementation risks with a single, robust ADP platform—no additional software licenses required.
5. Ensure data accuracy
Pull accurate information from every document with automated data extraction.
6. Improve user experience
Deliver information quickly and improve customer interactions. Simultaneously, enable your employees to focus on more value-added work.
What are the Core Components of Intelligent Document Processing?
An IDP platform should be:
- Flexible to extract, ingest, and validate data from unstructured, semi-structured, and structured documents.
- Industry agnostic.
- Scalable so that users do not have to train the API in case of minor changes in the document and be able to process a large number of documents.
- Capable of processing bulk documents through batch processing.
- Secure and end-to-end encrypted to prevent data leaks and privacy breaches.
- Offer third-party integrations across on-premise and cloud content management systems.
- Cloud-based so that it can be accessed from anywhere and across devices.
How Does IDP Work?
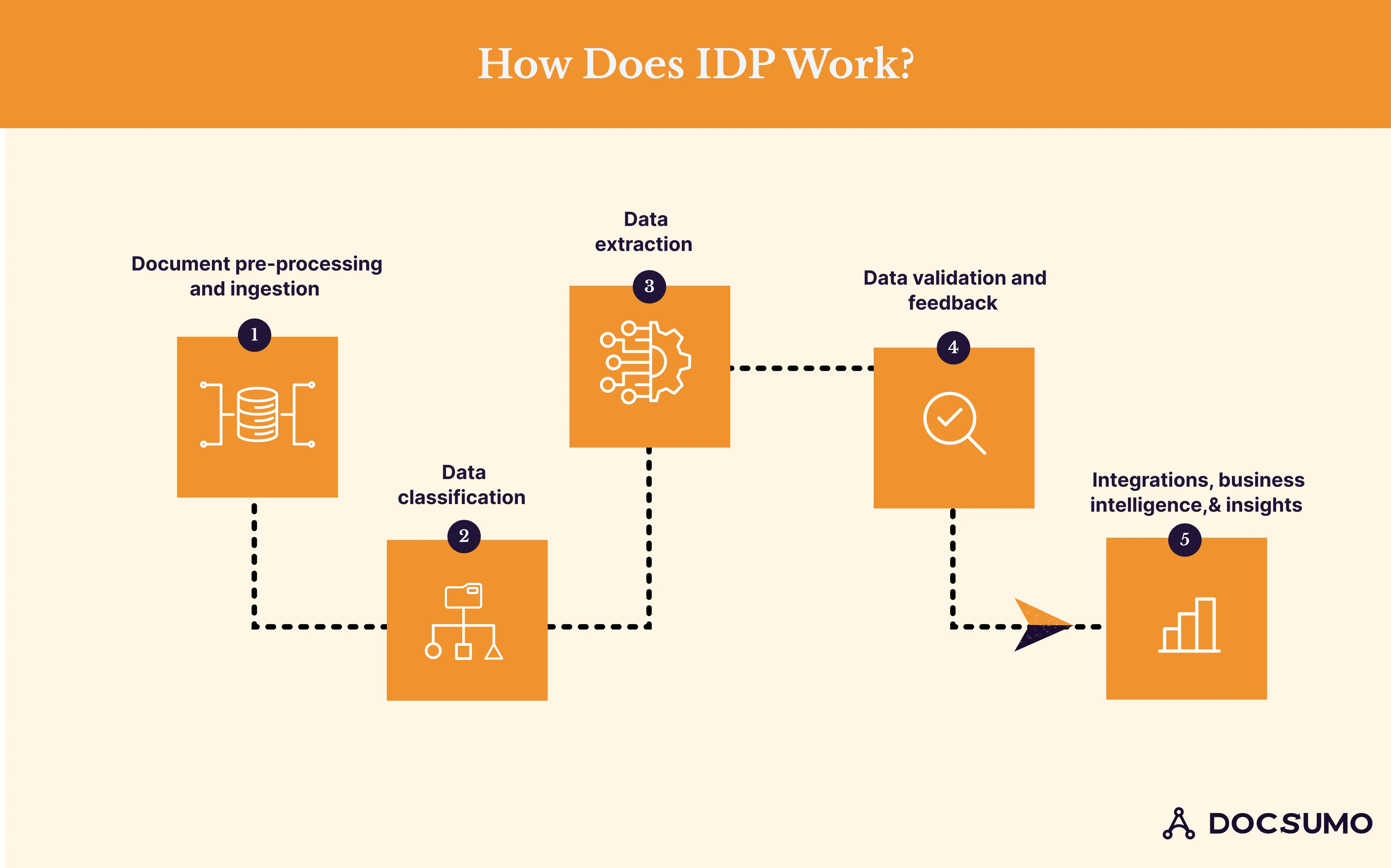
Intelligent document processing software uses machine learning to extract data from documents. There are five steps in the intelligent document processing workflow.
Step 1: Document pre-processing and ingestion
The first step in IDP is capturing data from multiple content types and preparing it for processing. Preparation involves merging or splitting of documents, data validation, and correction.
Some tools also allow data labeling and annotation for improved accuracy with human-in-the-loop.
Step 2: Data classification
Data is classified into different categories based on content and structure. Advanced solutions possess the capability to accept documents at scale and classify them to be routed to appropriate work queues.
Alternatively, the software offers suggestions for categories based on existing taxonomies. At this stage, humans can create categories and data validation.
Step 3: Data extraction
Machine learning allows the document processing software to extract data from various content types and allows the handling of diverse formats.
Advanced intelligent document processing software like Docsumo, Image to text by Prepostseo, etc. require almost no effort for quickly and accurately extracting data from images, PDFs, and many more. Humans can train ML models and APIs to identify fields for extraction.
Step 4: Data validation and feedback
IDP validates extracted data against business rules, document comparisons, and internal/external data to make sure that it is accurate. From here, the validated data goes for further processing whereas the data that fails validation is sent for correction.
Step 5: Integrations, business intelligence, and insights
Firstly, the validated data is sent to third-party software and downstream applications for use. Data enrichment tools, customer service platforms, and RPA solutions are common IDP integrations.
This data is then used for gathering insights, decision-making, and business process improvements. Ensure that the IDP software generates insights and can integrate with business sources for data to flow between different applications without manual intervention.
Some reasons for the widespread adoption of intelligent document processing solutions include:
- Its ability to process documents with text and image complexity.
- Text complexity - Footnotes, mixed font, text with images, long documents, and multiple documents within a PDF.
- Image complexity - Graphs, tables, noisy images, complex structures, and unusual elements.
- IDP can also process unstructured documents where the location and format have changed over time. For example, documents with the same data points are found in multiple locations with changed version, format, and source.
Benefits of IDP Over Other Document Processing Technologies
The answer is in its name: IDP is a subset of Intelligent Document Automation. The tool’s key advantage is its ability to understand the context of the data it’s reading and use it for extraction.
Here's a quick rundown of the benefits of Intelligent Document Processing (IDP):
1. Boosts document processing efficiency by 10X faster processing
IDP software automates document processing within seconds, unlike the hours that manual labor typically needs. Moreover, their document process automation handles large volumes of data in different formats with zero fatigue. But it doesn’t mean you lose control; human-in-the-loop remains crucial for critical reviews and approvals.
2. More than 99% accuracy in data extraction
Advanced IDP algorithms ensure highly accurate data extraction 24/7. Features like error flagging, email verification, and data verification further streamline this process.
3. Improves STP (Straight-through-processing) up to 95%
IDP platforms reduce the need for multiple touchpoints and manual data entry, resulting in faster, error-free transactions and significantly improved STP rates.
4. Operational costs reduce by 65-70%
Although IDP involves upfront setup costs, the long-term ROI is substantial. Manual errors go down, and so do your printing costs.
Cloud-based platforms like Docsumo also detect and flag anomalies, such as fraudulent payments and duplicate entries, further reducing costs.
5. Reduces data processing time to 30-60 seconds
IDP processes data and stores all extracted data in a centralized repository accessible by multiple teams. Quick processing streamlines workflows, enhances data quality and improves cross-functional team communication.
Modern IDP platforms also prepare data for Robotic Process Automation (RPA) by turning streams of unstructured data into cleansed, structured data.
6. Enterprise-grade security
In the current regulatory environment, security is a non-negotiable factor for growth. With features like audit trails, encryption, and compliance with GDPR and SOC-2, Docsumo has robust data security measures for all new-age enterprises.
7. Easy integration
Advanced IDP systems seamlessly integrate with your existing hardware and software tech stacks. This enables smoother data flow from various sources and faster data consolidation, which in turn leads to efficient digital workflows.
If you need a dependable and effective platform for your document processing automation, Docsumo is the go-to choice. Our self-learning AI cuts manual review time and cost by up to 70%.
Try Docsumo for Document Processing Automation
Docsumo’s intelligent document processing automation software enables businesses to extract data easily and efficiently from both structured and unstructured documents. The self-serve interface comes with pre-trained models for most common business documents so that you can get started immediately.
What makes Docsumo the best document processing software are the following features:
- NLP-based data categorization
- Auto-classification of documents
- Real-time validation, verification, and approval of data from the database
- Ingest documents from any channels
- Wide range of use cases across industries such as banking, insurance, lending, and logistics
If you’re planning to implement an IDP solution to automate your business’s document processing, sign up for a free trial.
FAQs
1. What is automated document processing?
Automated Document Processing (ADP) blends artificial intelligence (AI) with deep learning to extract data from your documents. It can handle documents irrespective of size, volume, and format (including but not limited to PDFs, images, and scanned documents).
2. What is the difference between IDP and RPA?
IDP stands for Intelligent Data Processing, while RPA is Robotic Process Automation. These data technologies often work together to streamline business processes.
- IDP focuses on extracting data from unstructured documents, such as invoices, contracts, and forms.
- RPA is ideal for automating repetitive, rule-based tasks within structured applications, like transferring data between systems.
3. What is the difference between OCR and intelligent document processing?
OCR (Optical Character Recognition) refers to a technology that converts the texts in images into machine-readable text. IDP (Intelligent Document Processing) is a broader term encompassing OCR and other technologies. IDP uses AI and machine learning to recognize and understand the context of the text it’s reading.
While OCR can recognize text, it may struggle with complex layouts, handwriting, or low-quality images. Overcoming this challenge, IDP facilitates more accurate data extraction and classification.
4. What is IDP in automation?
Intelligent Document Processing (IDP) is a critical component of automation initiatives. It enables businesses to automate tasks that were previously manual and error-prone, such as:
- Data entry
- Invoice processing
- Contract management
- Customer onboarding
- Compliance
5. Why is OCR used?
Optical Character Recognition (OCR) helps extract text from images and documents. Some of the notable areas of its applications are:
- Document scanning and digitization
- Text recognition in images
- Data extraction from forms
- Optical character verification
While OCR is a valuable tool, it has certain limitations when handling complex layouts, handwriting, or low-quality images. Intelligent Document Processing (IDP) can provide more accurate and reliable results in these cases.


.webp)
.webp)
.webp)