
Suggested
Utility Bills Definition

Managing and processing data efficiently has become a cornerstone for businesses striving to maintain a competitive edge.
“Automated workflows" might sound like a buzzword, but it holds immense value for companies overwhelmed by endless paperwork—documents that never seem to stop accumulating.
Imagine if the smallest details from your invoices or contracts could seamlessly transfer to your system, automatically organized into the exact structure you need.
That’s precisely the transformative power of automated data capture.
The significance of automated data capture is evident in its market growth. The global automatic identification and data capture market size was valued at USD 54.1 billion in 2023 and is projected to grow at a robust CAGR of 12.6% between 2024 and 2032.
This growth reflects the increasing adoption of automation technologies across industries to streamline workflows, reduce operational costs, and improve decision-making.
In this blog, we’ll cover everything you need to know about automated data capture.
Let’s get deeper into how automated data capture can transform your business operations and help you stay ahead in a competitive marketplace.
Data capture involves collecting organized or unorganized information and converting it into data that can be read and processed by a computer.
Essentially, you extract information from digital or paper documents and convert the captured data into a structured form so that it can be further utilized for storing, editing, and processing.
Data can be captured in two ways - a) Manual data capture and b) Automated data capture.
Let's evaluate the pros and cons of traditional vs. modern data capturing techniques:
Manual data entry or document capturing is the timeworn method of gathering information from various sources and entering it into a computer or manual files by hand. Even in the digital era, surrounded by technology, we can argue that manual data entry has its upsides.
The most obvious is how setting up a manual data collection process is easy and allows businesses to keep their data entry costs at a minimum.
Further, it raises employment opportunities, as even individuals with basic qualifications can perform manual data capturing. Another positive is that some documents are not intelligible for computers.
For example, the muddled script of an old handwritten letter can only be deciphered by the human gaze.
Certain company documents are highly classified or sensitive, and it is preferred that these be handled under human supervision.
However, as is true with most age-old methods that have been replaced by technology, manual data entry is prone to errors and can be time-consuming, especially if you're dealing with a copious amount of data collection.
Also, dynamic business environments demand that data be at your fingertips at all times. With manual data entry, it can be challenging to look for important information amidst a huge pile of documents.
Moreover, utilizing data further to gain insights can seem convoluted since information look-up in itself can be a tedious affair.
Automated data capture is the process of consolidating data and converting it into electronic files with the aid of tools and software such as Optical Character Recognition (OCR). The artificial intelligence of these tools, combined with machine learning, allows them to read files quickly and translate their content into handy digital files.

It is needless to say computer software can collect and store data at flashing speed without committing any errors.
Moreover, if your document-capturing solution provides cloud storage, you can easily save the collected information online without worrying about data losses. Also, it'll be much more convenient to access all the data as it'll simply be a search-and-click away.
Here, you can also integrate your document-capturing tools with Databricks to enhance data handling and analysis, providing deeper insights and improved management. This Databricks integration streamlines data processing and aggregation, leveraging the capabilities of big data platforms to increase the value of your automated systems.
Data entry automation solutions are always attractive due to the value and utility they offer. However, this often comes at the cost of your data's safety. Any information, once it is online, can be accessed by a cybercriminal willing enough to go through the pain of stealing it. This is why companies these days make relentless efforts to safeguard information.
Now that we’ve covered the basics of data capture, let’s explore OCR (Optical Character Recognition) data capture—a powerful technology that has transformed the processing of unstructured and paper-based data.
Optical Character Recognition (OCR) data capture is a technology that scans PDFs, images, and paper documents to convert data into editable and searchable texts. The software solution does this by recognizing different characters and comparing them with a trusted database of fonts to extract data.
The extracted data is then ready for detailed analysis, integration, and storage. Several industries, retail, lending, banking, government, real estate, healthcare, insurance, and logistics, now widely employ OCR technology to automate data extraction tasks.
Having understood what OCR data capture is and how it works, it’s time to look at the tangible benefits this technology offers. Let’s explore how automated OCR data capture can revolutionize business processes and drive efficiency
Automation OCR (Optical Character Recognition) offers many benefits that can significantly improve efficiency, accuracy, and compliance. This technology has become an indispensable tool for organizations across various industries, from healthcare to finance and beyond.
Automated data extraction using OCR systems ensures faster turnaround time of data even while processing large volumes of documents. This helps to deliver services on time, improving customer satisfaction and retention.
For instance, an insurance company processing hundreds of claims daily can extract name, age, phone number, policy details, and insurance amount in minutes. The company can then analyze the extracted data to ensure authenticity and swiftly initiate payments.
AI-based OCR solutions capture data with unmatched accuracy levels, greater than 90% for businesses across different industries. They use advanced validation rules to verify the extracted data and identify errors.
The system also constantly learns and updates to maintain and improve this higher accuracy rate.
Adopting OCR technology into document processing workflows reduces significant costs in hiring labor for data extraction. Businesses can also prevent additional costs on expensive errors caused by manual data entry. Thus, in the long run, OCR technology offers a great ROI with all these cost savings.
OCR systems can work 24/7 without breaks or downtime, handling all repetitive data capture tasks and relieving employees. This lets employees leverage their skills to contribute to high-value tasks, improving employee satisfaction and retention.
For instance, a business processing thousands of invoices per month can use OCR automation to extract data from invoices. This way, employees can concentrate on procurement strategies, vendor relationship management, and budgeting, improving business growth and expansion.
Most OCR data capture systems are GDPR, HIPAA, and SOC-2 compliant, helping businesses ensure compliance even with the strictest regulations. End-to-end data encryption, cloud storage, and access controls protect customer data against cybercriminals and malware attacks.
For example, a healthcare organization storing patients’ personal and financial data can easily maintain HIPAA compliance with OCR systems. Moreover, advanced security features ensure that patient data is safe and secure.
With the advantages of automated OCR data capture clearly laid out, a natural question arises—what’s the investment required to implement these systems? Let’s break down the costs and factors influencing them.
Here's a detailed breakdown of the costs involved in investing in an OCR data capture system:
Front-end costs for the OCR software for data entry system vary significantly according to the vendor. Some vendors might offer a “pay and forget” based pricing model for the OCR system, while others provide a flexible subscription or pay-as-you-go pricing method for businesses.
Factors such as removing outdated functionalities, improving performance, software validation and testing, and fixing bugs determine the maintenance costs for the OCR software for data entry. This is a recurring cost that businesses need to pay to maintain the OCR solution's optimal functioning.
This includes the training required for employees to leverage the OCR model and extract data. Some vendors provide training in-house, and some businesses outsource their training requirements to skilled professionals.
Besides these regular costs, businesses can expect costs for advanced features such as table extraction, handwriting recognition, and cloud processing functionalities. These costs can add up depending on the monthly document volume.
While knowing the costs of OCR systems is essential, the real question is—how do they measure up against manual data entry? Let’s get into a head-to-head comparison to see which approach truly delivers the edge for your business.
Traditional data capture is slow, tedious, and expensive. It's also prone to human error. Companies that benefit most from automation OCR technologies are those involved in payroll process and administrative tasks.
They can reduce the number of forms they must complete and speed up their submission process.
Manual data entry enters information from a paper document or image file into a computer application. The manual process of sorting through and entering data can quickly become a bottleneck for companies trying to scale their operations.
There are many challenges associated with manual data entry, including:
Conversely, automated OCR data capture can identify, extract, and classify useful information from documents. Among other advantages of OCR over manual data entry, the most significant is speed. OCR is fast, accurate, and reliable for handling your data entry needs.
Automated OCR software is more convenient because it does not require user intervention. Compared with manual data entry, automatic OCR systems are more economical.
Automated OCR data entry can instantly turn your product information into computer-readable text that shopping carts and other online systems can use. OCR software reads the text directly from images of items and then converts it into usable information, allowing you to quickly and easily upload it.
Understanding the potential drawbacks of OCR is essential to making informed decisions about its implementation. By acknowledging these limitations, businesses can mitigate risks and optimize their data capture processes for maximum efficiency and accuracy. Let’s explore some of the limitations in the next section of the blog.
OCR is imperfect; even the most basic text recognition software isn't infallible. For instance:
Despite the challenges, there are many other innovative data capture technologies available beyond OCR.
Let’s unfold them and learn in detail in the next section of this blog.
Out of a range of data-capturing technologies available today, let's explore the ones that revolutionized the landscape:
OCR extracts texts from documents, images, or files by scanning them. The information collected is converted into a machine-readable form so that it can be further used for processing, editing, recording, etc.
The technology essentially identifies text and characters inside images (for example, the image of a scanned document) and then translates it into a digital format.
In simpler terms, it is a form of data entry automation where information is directly pulled from scanned images and stored in a computer with the help of an OCR device. There is no manual data entry involved.
Another common example would include scanning a paper document and converting it into a PDF or Microsoft Word document and storing it on a digital device to edit or refer to later on.
Intelligent Character Recognition is a subset of OCR that specifically scans documents with handwritten text, identifies data from complex handwriting styles, and translates it into a computerized format.
Though ICR is essentially a branch of OCR, it is considered to be more advanced, as it deals with handwriting recognition, which is much more intricate and detailed.
No two handwritings are the same. An ICR software needs to scan, read, interpret, and commit to memory a myriad of handwriting patterns.
It contains an AI-based self-learning system called the neural network. When this system is introduced to a new document, it automatically learns the unique font, style, and pattern of the script on that document and updates its database with the knowledge. This helps the software predict new types of handwriting patterns with more accuracy.
ICR technology is continually evolving, as there are always new patterns to be learned and more precision to be achieved.
Modern-day businesses use ICR software to draw out information from hand-filled forms and save it digitally.
Document processing is not a new discipline for many businesses. It is the process of capturing information from documents (digital or physical) and storing that information on a computer to draw value and insight from it.
Much like manual data entry, manual document processing can't be relied on for smooth and precise data extraction. Human errors are common, and processing hundreds of documents for information verification fand urther analysis is a challenging feat to achieve, no matter how efficient your workforce strives to be.
Intelligent document processing automates all tasks involved in securing data from documents. And wait, the 'intelligent' in IDP is not just for automation. IDP technologies also extract unstructured or semi-structured information and categorize it for easier analysis. Meaning you can retrieve organized information in minutes and focus on the next step in your workflow.
IDP consists of five steps:-
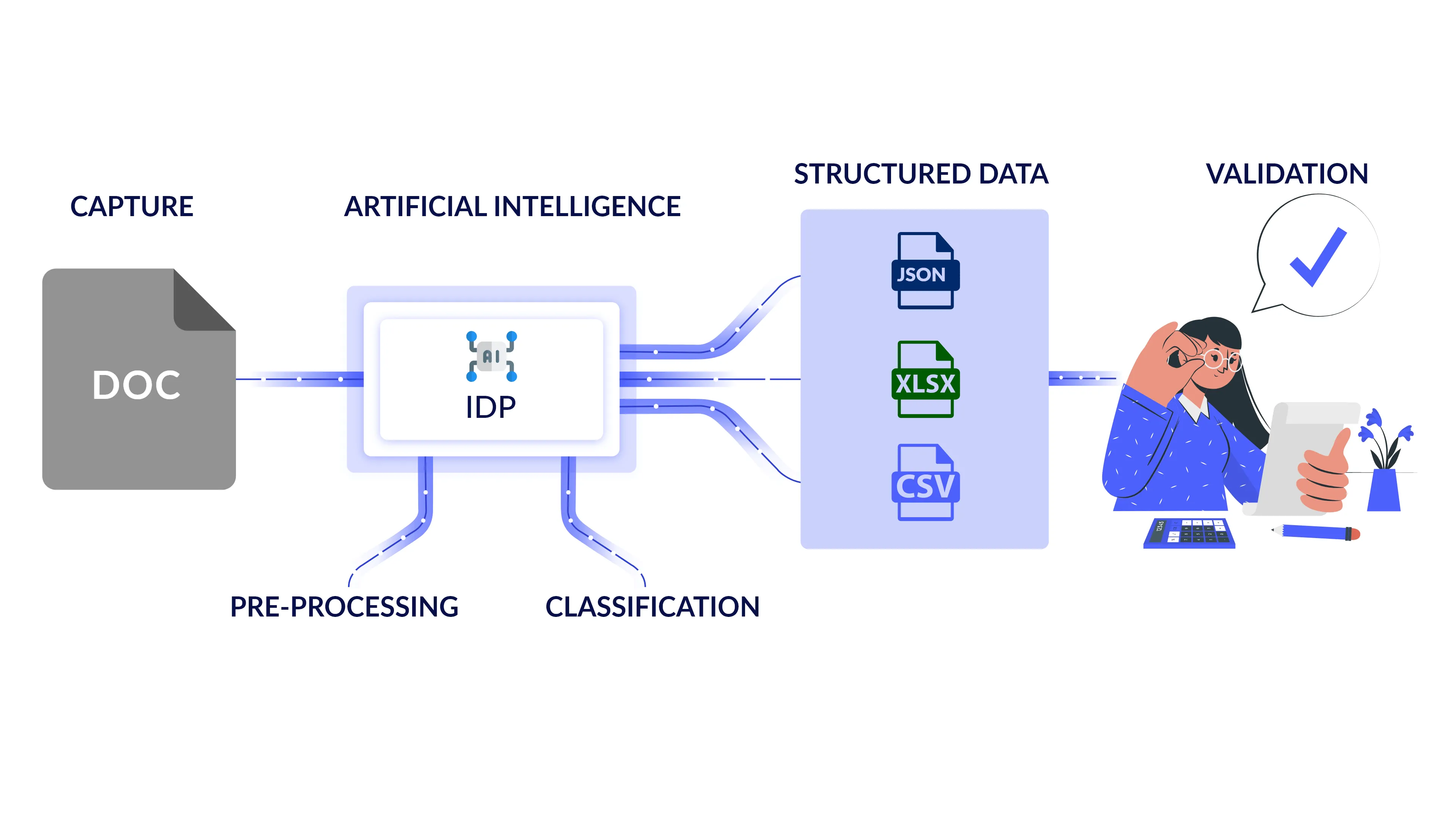
For example, a bank account application usually contains a set of documents which include a form, identity proofs, residence proofs, etc. IDP will recognize each document for what it is and send it in the appropriate workflow.
These advanced data capture technologies offer significant benefits across a wide range of industries. Let's explore how businesses in different sectors can utilize automated data capture to improve efficiency, reduce costs, and gain valuable insights.
Let's look at a few common use cases for automated data capture to understand its relevance in today's world.
Accountancy firms benefit from automated data capturing heavily by:
Insurance companies need to collect a lot of information from their customers.
Automated document capturing helps these companies by:
Data capturing technologies can efficiently handle large amounts of banking data by:
HR is another discipline that heavily relies on data for day-to-day operations. Through document-capturing solutions, HRs can:
Choosing the right document capture solution can significantly impact your business's efficiency and productivity. Let's explore the key factors to consider when making this important decision.
There's a lot to consider while choosing a document capturing solution. Prioritize the following and pick a solution befitting your needs:
Your data entry solution shouldn't have a steep learning curve. Of course, working with document capture solutions needs some kind of assistance from the vendor in training and educating about its features. Still, the training should be so smooth that even a non-technical background person can easily be able to handle it.
Don't fall for 100% error-free claims. Data capturing technologies are always evolving and learning from new patterns or past processing mistakes. A solution that promises an accuracy level between 95-98% is considered to be at par with industry standards.
The success of a document-capturing solution is centered not just on its accuracy rate but also on its ability to validate data automatically. Suppose all fields have to be evaluated manually for discrepancies. In that case, it kills most of the basic objectives of buying into a data entry automation software- ease of use, time-saving, minimal human intervention, etc.
Cheap rates don't necessarily mean that the services offered are subpar, and enterprise-level pricing doesn't guarantee top-drawer experiences. Keep this in mind while choosing your document-capturing solution, and measure your cost against the value/features offered.
Valuable and sensitive data is always vulnerable to cyber attacks. Your solution should follow all the prescribed protocols like GDPR compliance, OWASP practices, data center proxies, end-to-end encryption, limited admin access, etc. Also, look for data storage policies that allow you to decide what you do with your old data.
Docsumo guarantees a 50% increase in efficiency and a 70% reduction in processing costs. Let's see how:
a) Extraction
Pull clear details from structured, unstructured, or semi-structured data swiftly. Docsumo's APIs are pre-trained for common document types like forms, invoices, bank statements, and identity cards.
b) Classification
You can classify documents conveniently without having to open individual PDFs or images. Docsumo's intelligent classification sorts large documents into their corresponding types intuitively, without you having to write custom rules.
Its easy-to-follow interface allows you to keep track of all the documents your customers have submitted with clarity without needing to reach out to them for confirmations.

c) Analytics
Docsumo categorizes all data points and table line items using NLP. You can gain an insight into the properties of the captured data and utilize it for processing or analysis at the later stages of your workflow. Moreover, Docsumo turns disorganized information into valuable details that can help you make data-driven decisions with certainty and confidence.
d) Validation
You can verify captured information with Docsumo's external APIs and vast database and identify mistakes easily. Docsumo facilitates entity matching across documents to ensure that the information your customer has entered is correct. Moreover, you can check for the legitimacy of the information procured as Docsumo is quick to detect document fraud such as incorrect metadata, font changes or, added layers.
Integrations are important to streamline your operation workflows, which is why they are an inherent part of Docsumo's interface. You can use plug-in APIs and input and output connectors to easily synchronize the platform with other essential software like Zapier, Webhooks, Salesforce, Google docs, etc.
Docsumo is GDPR compliant and follows all protocols stipulated by OWASP. All server requests are transferred over HTTPS, and data exchanges are encrypted with AES 256.
For your satisfaction, Docsumo gives you the option to delete data from its servers (instantly or periodically) once data processing is complete. Its advanced user management also empowers you to keep an eye on who can access your data.
Docsumo promises to achieve 98% accuracy during information capturing and processing in one go. It has considerable experience in working with clients in financial services, commercial real estate, accounts payable, lending, insurance, and logistics.
Save 100+ hours a month by automating all your low-impact tasks so that your team can prioritize faster and accurate business decisions, every time.
Get Your Free Trial Today
.webp)