OCR for Invoices Processing: How OCR Simplifies Data Extraction from Invoices?
Optical Character Recognition (OCR) invoice processing involves automated data extraction from invoices using specialized software. Read the blog to learn how to use OCR for invoice data extraction, such as vendor details, invoice numbers, and amounts, to improve overall operational efficiency.

Invoice processing is a critical function for any business, involving the meticulous entry, verification, and management of financial data. Traditionally, this process has been highly manual, requiring significant time and effort from accounts payable departments to ensure accuracy and timeliness.
Manual invoice processing often leads to errors, delays, and inefficiencies, negatively impacting cash flow management and overall operational productivity. Optical Character Recognition (OCR) technology can be a game-changer in invoice processing.
OCR automates data extraction from various documents, including invoices, converting them into machine-readable text quickly and accurately. This optimizes the invoice processing workflow and significantly reduces the manual labor involved, enhancing efficiency and accuracy.
In this blog, we get into how OCR can transform how your business handles invoice processing. From understanding the basics of OCR to exploring its benefits and implementation steps, this is a comprehensive guide to leveraging it for efficient invoice management. Let’s start with the basics to understand what OCR is in invoice processing.
What is OCR in Invoice Processing?
Optical Character Recognition is a technology that modernizes invoice processing. In essence, OCR converts documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data.
When applied to invoice processing, OCR scans and reads the text from invoices, converting it into machine-readable text that can be easily stored, searched, and manipulated within accounting systems. It automates the extraction of key data fields from invoices, such as invoice numbers, dates, vendor details, line items, and total amounts. By transforming these data points from static images or PDFs into dynamic text, OCR significantly enhances the efficiency of the accounts payable process.
Manual data entry tends to errors and inefficiencies, and it has become a thing of the past. Instead, OCR has several benefits: It facilitates the rapid and accurate extraction of data, ensuring the information is immediately available for further processing and analysis. This automation speeds up the invoice processing cycle and ensures higher accuracy and consistency in financial records.
Before getting into more details about OCR, let's answer your question about How automated invoice processing differs from the traditional manual approach and what are the key advantages of automation. Let's explore.
Difference between manual and automated invoice processing

Let's have a look at the steps involved in each invoice processing method to explain the difference clearly:-
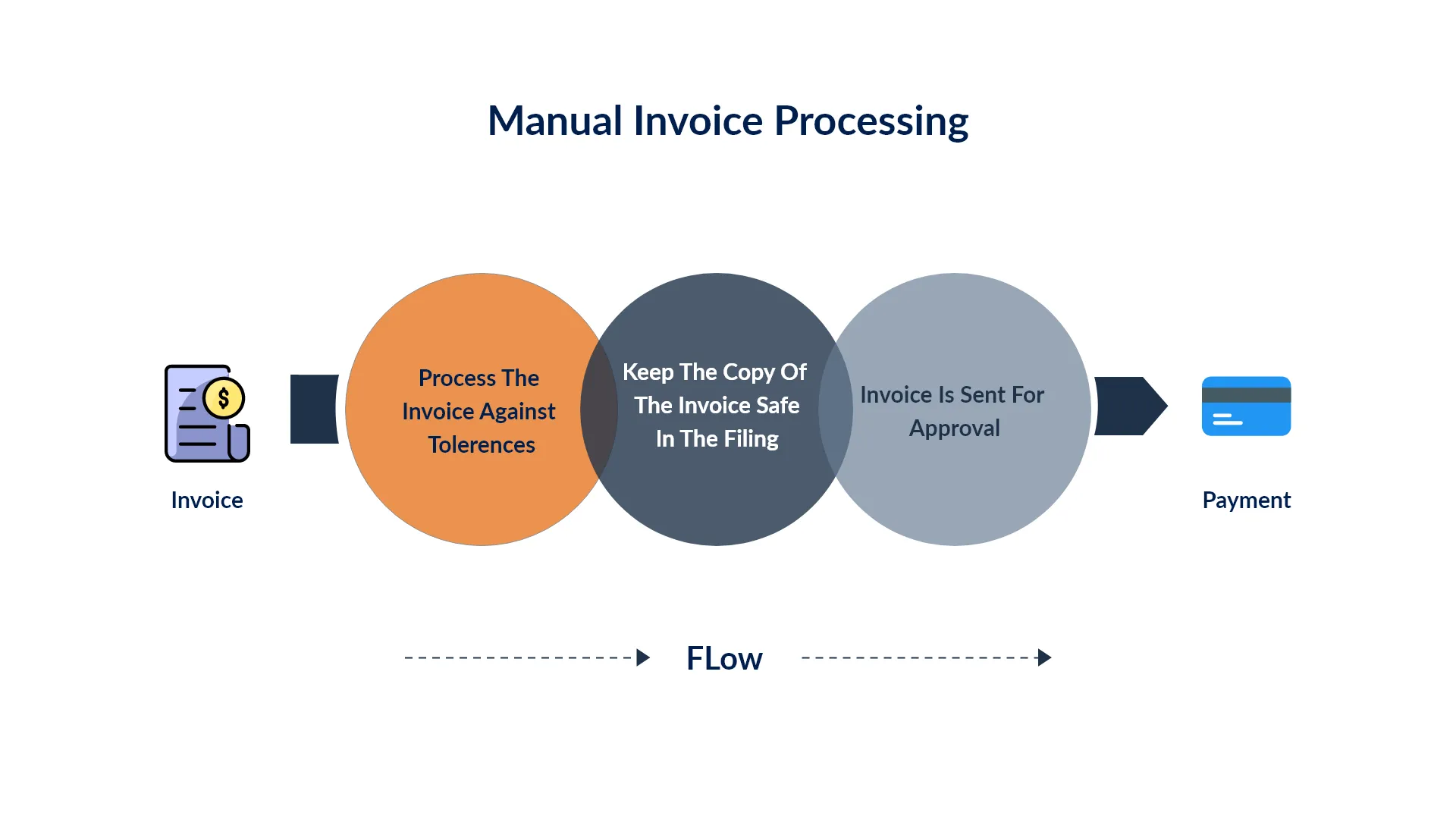
Manual Invoice Processing Steps
Starting from receiving an invoice to the payment clearance, when each step of the process is performed manually, is called manual invoice processing.
Step 1: Receiving invoice from vendor - An invoice is sent before or after the delivery of products/services based on the agreement between two parties. After that, the accounting team manually enters data into the accounting system.
Step 2: Process the invoice against tolerances - This step is specific to PO invoices. The received invoice is processed by 2-way, 3-way, or 4-way match processing methods against the purchase order(PO) for pre-defined tolerances.
Step 3: Keep the copy of the invoice safe in the filing system - After entering data into the accounting system and processing against tolerances, the invoice is scanned and kept safe in the filing system. Often, physical copies of invoices are kept safe as well.
Step 4: Invoice is sent for approval - Based on the size and structure of a company, an invoice is sent for approval for the payment. In small businesses, there may be 1 or 2 people with the authority and responsibility to approve invoices for payment, whereas in large businesses and enterprises, a whole team is responsible for invoice approvals.
Step 5: Make the payment - Once the invoice is approved, the payment is made.
Despite being time-consuming and needing a lot of manual effort, this process is not free of errors. Automated invoice processing makes it easier to extract information from an invoice, validate it, and keep it safe in the accounting system. Not only does it reduce manual efforts thus reducing the cost, but it is more efficient and accurate as compared to manual invoice processing.
Automated Invoice Processing Steps
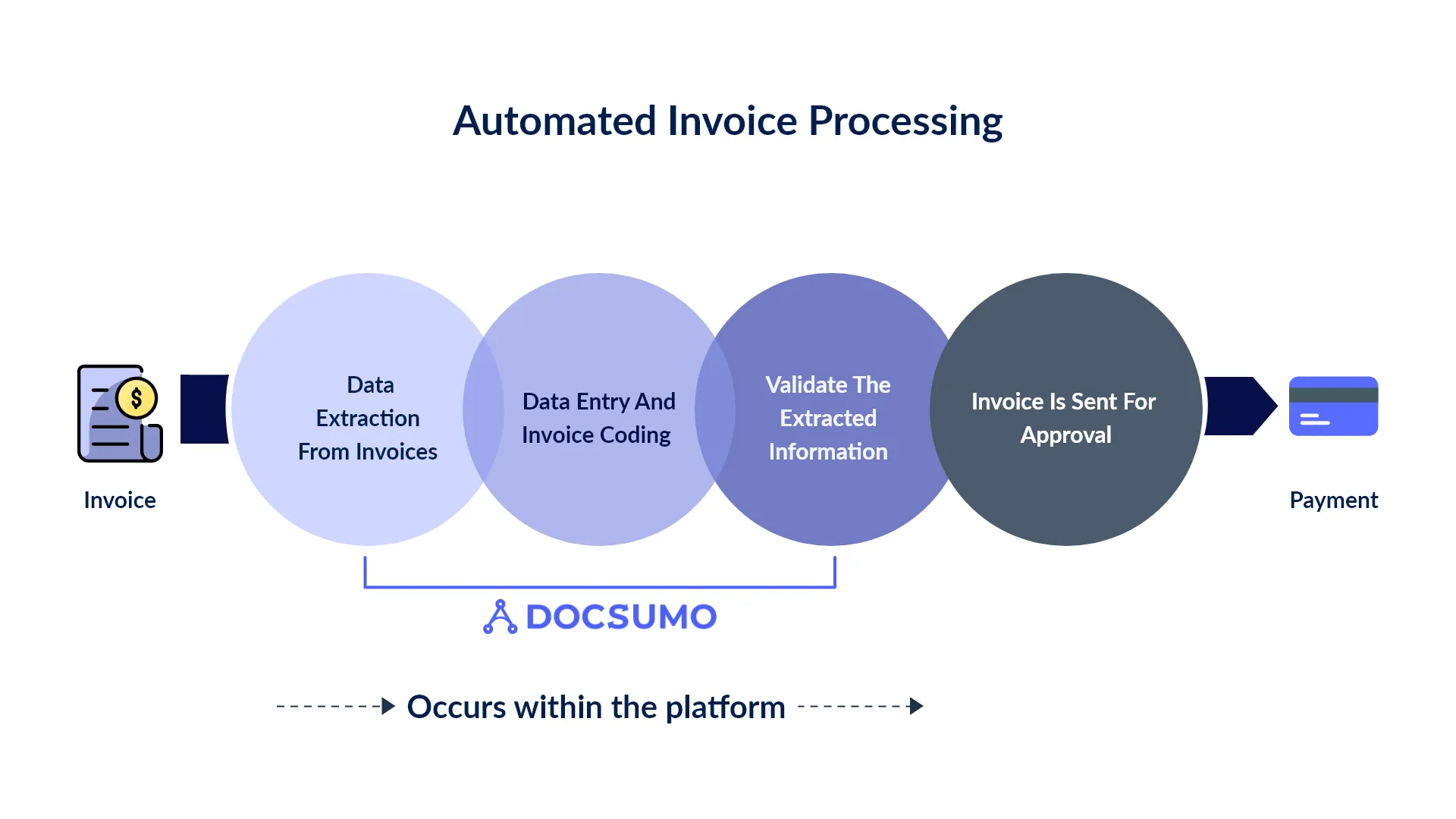
Step 1: Data extraction from invoices - Invoices vary in terms of layout, structure, and fields, but with the help of Intelligent OCR and machine learning technology, an automated invoice capture tool seamlessly adds invoice data, whether it be from paper invoices or electronic invoices sent through Electronic Data Interchange.
Step 2: Data entry and invoice coding - Data entry and coding are achieved through Intelligent Data Capture mechanisms that identify and extract data for processing into your invoice management system, which, depending on your software’s capability, will only need your AP professional’s minimum supervision or none at all.
Step 3: Validate the extracted information - After data extraction and invoice coding, the invoice processing software validates the captured data for pre-defined validation rules. If it doesn’t meet the set standard and any anomaly is found, it is routed for manual verification.
Step 4: Invoice is sent for approval - This phase is also a tedious step as it needs complex logical solutions and constant follow-up. Usually, the Enterprise Resource Planning and the Enterprise Content Management systems are used in this phase to manage notifications, follow-ups and to assign approval tasks.
Step 5: Make the payment - Finally, the payment is made after the approval.
Let’s take a look at the table below that effectively summarizes the key differences between manual and automated invoice processing!
Now that we understand the stark contrast between manual and automated invoice processing let's explore how Optical Character Recognition (OCR) technology plays a pivotal role in streamlining this crucial business function.
How does OCR help in Invoice processing?
OCR technology fundamentally transforms invoice processing by automating the data extraction process. This automation addresses several pain points inherent in traditional manual invoice processing, such as time consumption, high error rates, and inefficiency.
Let's get into the details of how OCR technology helps streamline invoice processing.
- One of the primary benefits of OCR in invoice processing is the acceleration of the entire workflow. Traditionally, processing an invoice manually involves several steps: receiving the invoice, manually entering data into accounting systems, validating the data, and then approving and making the payment. Each of these steps is time-consuming and prone to human error.
- But OCR automates the data entry part of this process. By quickly scanning and extracting data from invoices, OCR software reduces the time spent on manual entry. This enables faster document processing times, allowing businesses to handle more invoices with the same resources. The automation also ensures that data is captured accurately, which helps in reducing the time spent on corrections and rework.
- Further, manual data entry is not only slow but also labor-intensive. It requires dedicated staff to handle the influx of invoices, enter data, and verify its accuracy. This manual process is prone to errors such as typos, missed entries, and incorrect data entry, which can lead to significant discrepancies in financial records.
- OCR eliminates the need for manual data entry by automatically extracting information from invoices. This significantly reduces the workload on the accounts payable team, allowing them to focus on more strategic tasks such as managing vendor relationships and optimizing cash flow. Moreover, by minimizing manual intervention, OCR reduces the likelihood of errors, thereby improving the overall accuracy of invoice processing.
Through the above, OCR brings about significant improvements in both efficiency and accuracy. With OCR, invoices can be processed in a fraction of the time it would take manually. The extracted data is then directly integrated into the accounting software, ensuring that the information is accurate and up-to-date.
Examples:
- A company receiving hundreds of invoices monthly can use OCR to extract data fields such as invoice numbers, dates, vendor names, and amounts due. This data is then validated against the purchase orders and receipts within the accounting system, ensuring consistency and accuracy. The process speeds up the workflow and ensures that the data is reliable, thus reducing the risk of financial discrepancies.
- Consider a large retail company that processes thousands of invoices each month. By implementing OCR technology, the company can automate the extraction of key data from these invoices. The OCR software scans each invoice, extracts the relevant data, and uploads it to the company’s accounting system. This process, which once took several days of manual effort, can now be completed in a matter of hours, with minimal human intervention and higher accuracy.
- Another example could be a manufacturing firm that receives invoices in various formats—some as PDFs, others as scanned images. Through OCR, the firm can standardize the data extraction process across all these formats, ensuring uniformity and consistency in its accounts payable records. This enhances efficiency and enables the firm to have a clear and accurate view of its financial obligations at any given time.
For more on how automation speeds financial workflows, read our blog on invoice processing automation.
Now that we understand how OCR facilitates the automation of invoice processing, let's explore the key benefits that this technology can deliver to your businesses.
Benefits of Using OCR for Invoice Processing
The adoption of OCR technology in invoice processing offers numerous benefits, transforming how businesses handle their accounts payable operations.
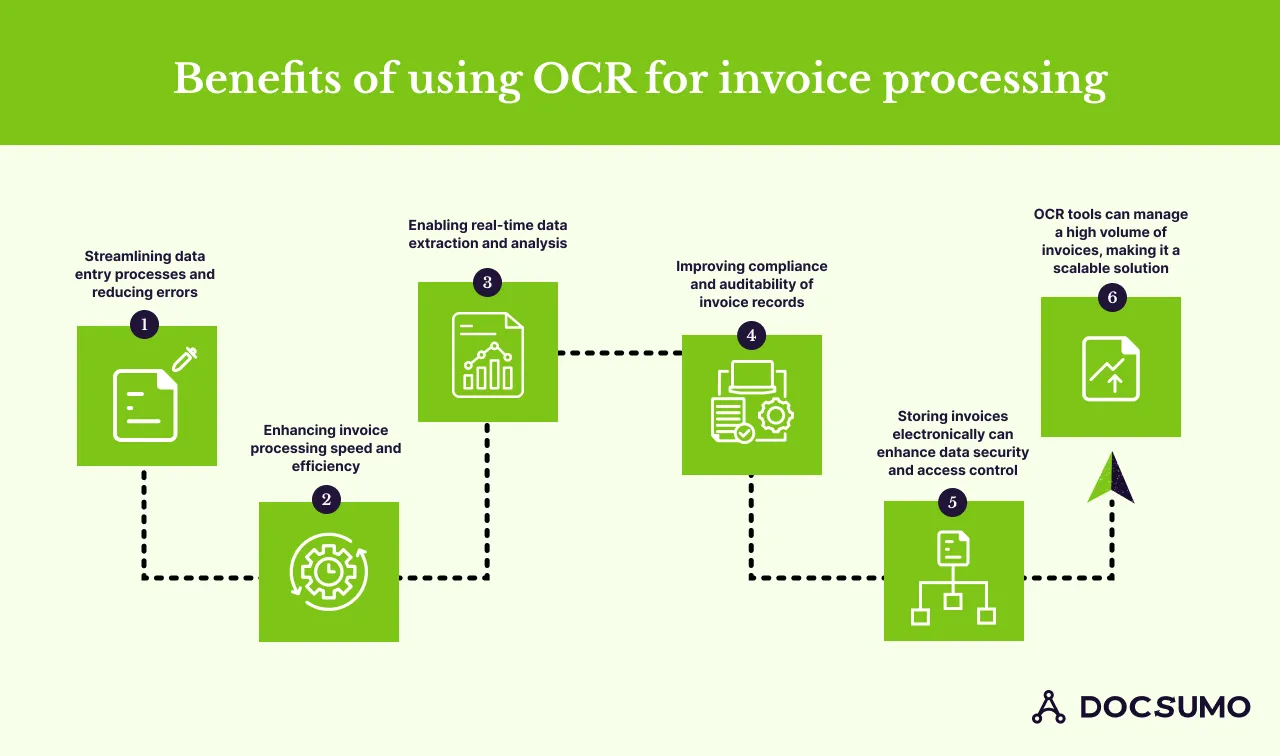
Here’s a detailed look at the key advantages:
1. Streamlining Data Entry Processes and Reducing Errors
One of the most significant benefits of OCR is the automation of data entry processes. Manual data entry is not only time-consuming but also prone to errors. OCR technology eliminates the need for human intervention by automatically extracting data from invoices and inputting it into accounting systems. This automation reduces the likelihood of errors such as typos and missed entries, ensuring greater accuracy and consistency in financial records.
2. Enhancing Invoice Processing Speed and Efficiency
OCR dramatically speeds up the invoice processing cycle. By automating the data extraction process, OCR reduces the time it takes to process each invoice from hours or days to just minutes. This increased speed allows businesses to handle a higher volume of invoices with the same resources, improving overall operational efficiency. Faster processing times also mean that businesses can take advantage of early payment discounts offered by vendors.
3. Enabling Real-time Data Analysis
With OCR, businesses can achieve real-time data extraction from invoices. This immediate access to invoice data enables faster decision-making and more timely financial reporting. Real-time data also allows businesses to monitor their cash flow more effectively, ensuring that they have an accurate picture of their financial position at any given moment.
4. Improving Compliance and Audibility of Invoice Records
Compliance and auditability are critical aspects of accounts payable management. OCR enhances both by ensuring that all invoice data is captured accurately and consistently. The technology creates a digital trail of every invoice processed, making it easier to audit records and verify compliance with internal policies and external regulations. This digital record-keeping also simplifies the audit process, as all necessary documentation is readily available and easily accessible.
5. Enhancing Data Security and Access Control
Storing invoices electronically using OCR improves data security and access control. Digital invoices are less susceptible to loss or damage compared to paper documents. OCR systems often include advanced security features, such as encryption and user access controls, which protect sensitive financial information from unauthorized access. Additionally, electronic storage allows for easier retrieval of invoice data, improving operational efficiency and supporting disaster recovery plans.
6. Scalability to Handle High Volumes of Invoices
OCR technology is highly scalable, making it suitable for businesses of all sizes. Whether a company processes a few hundred or several thousand invoices per month, OCR can handle the workload efficiently. This scalability ensures that as a business grows and its invoice volume increases, the OCR system can continue to support its needs without requiring significant additional resources.
Despite its significant benefits, OCR technology also presents certain challenges that businesses must consider when integrating it into their invoice-processing workflows. Let's explore these challenges.
Challenges of Using OCR in Invoice Processing
While OCR technology offers significant benefits in automating invoice processing, it is not without challenges. Understanding these challenges is crucial for effectively implementing and utilizing OCR solutions in your business.
- Accuracy: Although this is also one of its key benefits, one of the primary challenges with OCR for invoice processing automation can be accuracy. OCR systems can struggle with interpreting handwritten or poorly printed text. Variations in fonts, sizes, and document layouts can also lead to misinterpretation of characters, resulting in incorrect data extraction.
- Formatting Variability and Standardization: Invoices come in various formats and layouts, which can challenge OCR systems. Standardized documents are easier for OCR software to process, but many businesses receive invoices in non-standard formats with different structures, logos, and designs. This variability can complicate the OCR process and necessitate additional configuration and customization to capture data from all invoice types accurately.
- Support Multiple Languages: OCR systems also need to support multiple languages to be effective in a global business environment. While many OCR solutions are proficient in recognizing common languages, handling invoices in less common or multiple languages can take time and effort. Businesses must ensure that their chosen OCR software can accurately process invoices in all the languages they encounter.
- Data Privacy and Security: OCR technology involves digitizing and processing sensitive financial information, which raises concerns about data privacy and security. Businesses must ensure that their OCR solution adheres to relevant data protection regulations and implements strong security measures, such as encryption and access controls, to safeguard sensitive information from unauthorized access and breaches.
- Integration with Existing Software: Integrating OCR software with existing accounting systems and workflows can be complex. Ensuring seamless integration requires technical expertise and may involve significant time and resources. Choosing an OCR solution with robust integration capabilities and support can help ease this process and ensure that the OCR system works harmoniously with other business applications.
Despite the challenges, OCR technology can effectively extract a wide range of critical data fields from invoices, significantly improving the efficiency of the entire processing workflow. Let's explore.
Fields That Can be Extracted From Invoices Using OCR
OCR technology is designed to recognize and extract various critical data fields from invoices, transforming them into structured, machine-readable formats. This ability to capture essential details accurately and efficiently is fundamental to improving the invoice processing workflow.
Here is the list of fields that can be extracted from invoices using OCR:
- Invoice Number: OCR software can identify and extract unique invoice numbers, which are crucial for tracking and referencing transactions.
- Invoice Date: The date of the invoice is another essential field that OCR systems can capture, aiding in the timely processing and payment of invoices.
- Vendor Details: OCR technology can extract vendor information, including the vendor’s name, address, and contact details. This ensures accurate recording and facilitates vendor communication.
- Line Items: One of the most complex aspects of invoice processing, OCR can capture detailed line items, including descriptions, quantities, unit prices, and total amounts for each item listed.
- Total Amount: OCR systems can extract the total amount due, including subtotals, taxes, and the final payable amount, ensuring financial records are accurate and complete.
- Payment Terms: Terms and conditions related to payment, such as due dates and early payment discounts, can also be extracted to manage cash flow effectively.
- Purchase Order Numbers: Linking invoices to corresponding purchase orders is crucial for validation, and OCR can capture these numbers to streamline the matching process.
OCR technology is also versatile and can handle various invoice formats, including:
- Paper Invoices: Traditional paper invoices can be scanned and processed using OCR to convert them into digital, searchable formats.
- PDF Invoices: OCR can extract data from PDF invoices, which are commonly used in electronic transactions.
- Electronic Invoices (e-Invoices): These invoices are designed for electronic data interchange (EDI) and can be directly processed by OCR systems without the need for scanning.
Now that we understand the types of data that can be extracted, let's explore the practical steps and techniques involved in extracting this information from invoices using OCR technology.
How to Extract Data from Invoices Using OCR
Implementing OCR for invoice processing involves several crucial steps to ensure accurate data extraction and seamless integration into your accounting systems.
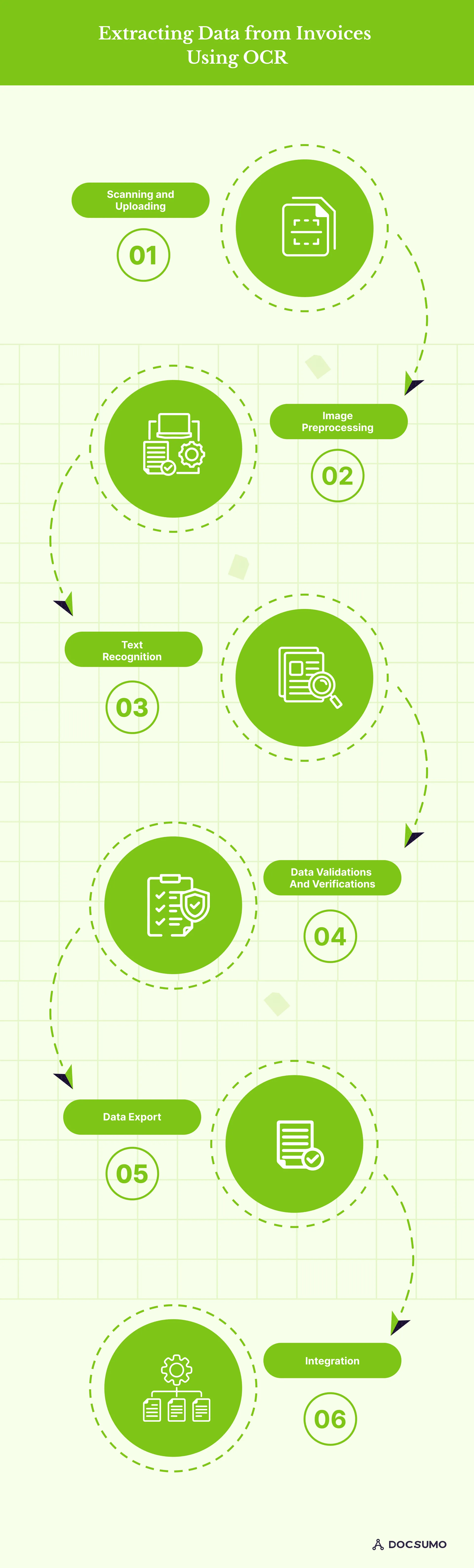
Here is a step-by-step overview of the process:
1. Scanning and Uploading
The first step in using OCR is to scan the paper invoices or upload digital invoices into the OCR system. High-quality scans are essential for accurate data extraction. Documents should be clear, without smudges or distortions, to enable the OCR software to read them effectively.
2. Image Preprocessing
Before the actual OCR process begins, image preprocessing techniques are applied to enhance the quality of the scanned documents. This may include adjusting the brightness and contrast, removing noise, and correcting any skewed or rotated images. These adjustments improve the accuracy of the OCR system.
3. Text Recognition
Once the document is preprocessed, the OCR software performs text recognition. It analyses the document and converts the text from images into machine-readable characters. Advanced OCR systems use sophisticated algorithms to identify different fonts, sizes, and languages to extract text accurately.
4. Data validation and verification
After text recognition, the extracted data undergoes validation and verification to ensure accuracy. This involves checking the data against predefined rules and standards. For instance, invoice numbers are validated to ensure they are in the correct format, and total amounts are checked for consistency with line item totals.
5. Data Export
Validated data is then exported into structured formats, such as CSV, XML, or directly into accounting software. This allows for easy integration with other business systems, enabling seamless data flow and reducing manual entry errors.
6. Integration
The final step is integrating the OCR-extracted data with existing accounting systems and workflows. This may involve configuring the OCR system to automatically feed data into ERP systems, accounting software, or other financial management tools. Proper integration ensures that the data is used effectively within the organization, enhancing overall efficiency.
To illustrate the practical application of these techniques, let's examine a real-world example: Valtech's successful implementation of Docsumo's OCR-powered invoice automation solution.
Real Impact with Docsumo: Valtech Achieved 3X Faster Invoice Processing, 98% Accuracy with OCR
Valtatech, a managed services provider in Melbourne, Australia, faced significant challenges in managing its invoice processing workload. As discussed above, manual data entry is time-consuming and prone to errors, leading to delays and inefficiencies in the accounts payable operations.
But by implementing DocSumo’s OCR solution, Valtatech was able to automate the extraction of key invoice data, reducing the invoice processing time from a few hours to less than 5 minutes with 99% accuracy.
DocSumo’s solution enables an API-based direct integration, allowing seamless ingestion of invoices onto the DocSumo platform. DocSumo's inbuilt document pre-processors then identified various formats, such as JPG, PDF, and PNG, and prepared them for data extraction.
Utilizing its powerful OCR module, DocSumo then extracted data from unstructured text with remarkable accuracy. The OCR parsed through invoices with different fonts, layouts, image qualities, and resolutions, achieving over 95% accuracy, even with table data. This was further enhanced by DocSumo’s proprietary NLP-based classification framework, which quickly learned to categorize key-value pairs and line items. An intelligent algorithm also made accurate predictions to identify the data within invoices.
Following data extraction, a rule-based validation engine applied contextual validation and correction algorithms to ensure data integrity. Finally, the extracted and validated data is seamlessly integrated with Valtatech's downstream software, creating a smooth and efficient invoice processing workflow.
By implementing DocSumo, Valtatech achieved a more efficient, accurate, and automated invoice processing system, showcasing DocSumo's capability to transform complex data extraction tasks.
DocSumo: The Best OCR software for Invoice Processing
When it comes to OCR solutions for data extraction and invoice processing, DocSumo stands out as a leading choice. Designed to address the unique challenges of managing invoices, DocSumo offers a comprehensive suite of features that streamline data extraction, enhance accuracy, and facilitate seamless integration with existing financial systems.
- Advanced data extraction algorithms: DocSumo leverages advanced OCR algorithms that accurately extract data from a variety of invoice formats, including paper, PDF, and electronic invoices. These algorithms are trained to recognize and process complex invoice structures, ensuring that key fields such as invoice numbers, dates, vendor details, and line items are captured precisely. This level of accuracy reduces the need for manual corrections and significantly speeds up the invoice processing workflow.
- Seamless integration options: One of the standout features of DocSumo is its ability to seamlessly integrate with a wide range of accounting and ERP systems. Whether your organization uses popular platforms like QuickBooks, SAP, or custom financial software, DocSumo can be configured to feed extracted data directly into your existing systems. This integration capability eliminates the bottlenecks associated with manual data entry and ensures that your financial records are always up-to-date and accurate.
- User-friendly interface: DocSumo’s user interface is designed for ease of use, making it accessible to users with varying levels of technical expertise. The platform provides intuitive tools for uploading and managing documents, configuring OCR settings, and reviewing extracted data. This simplicity enhances user adoption and minimizes the learning curve associated with implementing new technology.
- Robust compliance and security features: In today’s regulatory environment, ensuring the security and compliance of financial data is paramount. DocSumo is built with robust security features that protect sensitive information and ensure compliance with relevant data privacy regulations. Features such as data encryption, secure access controls, and regular audits provide peace of mind that your financial data is protected at all times.
- Scalability to handle high volumes: DocSumo offers the scalability needed to manage large workloads efficiently for businesses dealing with a high volume of invoices. The software can process thousands of invoices daily without compromising speed or accuracy, making it an ideal solution for growing businesses and enterprises looking to optimize their invoice-processing operations.
You can discover the above benefits more quickly by scheduling a free demo with DocSumo.
Frequently Asked Questions
What is automated invoice processing?

Automated invoice processing uses technology, such as OCR, to automatically capture, extract, and process data from invoices without manual intervention. This enhances efficiency and reduces the risk of errors.
What is invoice OCR?
Invoice OCR is the application of Optical Character Recognition technology to convert invoice data into machine-readable text. It extracts key information like invoice numbers, dates, and vendor details from digital or scanned invoices.
How to select the best OCR invoice processing software?
Consider factors such as accuracy, integration capabilities, ease of use, scalability, and compliance with data security standards. Evaluate software solutions through demos and user reviews to find the best fit for your business needs.
Who uses invoice processing software?
Invoice processing software is used by a variety of businesses, including small enterprises, large corporations, accounting firms, and finance departments within organizations, to streamline and automate their accounts payable processes.
How do you digitise an invoice?
To digitize an invoice, scan the physical document or convert the digital file into a machine-readable format using OCR software. The software then extracts the relevant data fields, which can be validated and integrated into your financial systems. By embracing OCR solutions like DocSumo, businesses can transform their invoice processing operations, driving efficiency, accuracy, and growth.
