
Suggested
Utility Bills Definition
Since IDP and OCR are both data extraction technologies, they are often used interchangeably, or IDP is considered just another repackaged version of traditional OCR. As a business decision maker, it’s important for you to understand the difference between two to figure out which one is better suited for your business requirements. Traditional OCR costs less but works only with template based standard documents, whereas IDP solutions are able to offer you the flexibility to work with semi-structured/unstructured documents with increased accuracy using AI, Machine Learning, Deep Learning, and of course, OCR.
What’s the difference between two technologies and how similar are they? Most importantly, which one do you need for your business? - We answer all of these questions in this blog.
So, let’s jump right into it:-
Extracting data from documents is essential for almost all businesses. To perform this task, you have three choices:-
While manual data extraction from documents can get laborious and yield lower accuracy, OCR has its own limitations with colored backgrounds, glaring, and improper data structuring. To overcome these limitations, Intelligent Document Processing and related technologies have been developed over the years.
Limitations of manual data extraction are well understood and beyond the scope of this article. If you’re interested, you can read about it in this article here - Problems with Manual Data Entry and How to Resolve them, and let’s move forward to the definition of OCR:-
Optical Character Recognition converts a scanned image into text by transcribing it one character at a time. Simply put, OCR converts an image(with text) into machine-readable text.

The technology works really well with simple template-based documents but fails when there is a variation in the layout or template of a document type.
The next generation of the OCR is template based OCR or zonal OCR, which is able to recognize a block of text or a ‘zone’ in a document and extract data based on these ‘smart zones’. Zonal OCR is fairly useful in key-value pair extraction but a slight variation in the document template can lead to failure.
So, far we’ve established that:-
Intelligent Document Processing (IDP) overcomes all these limitations with the additional help of AI, ML, and Deep Learning technologies.
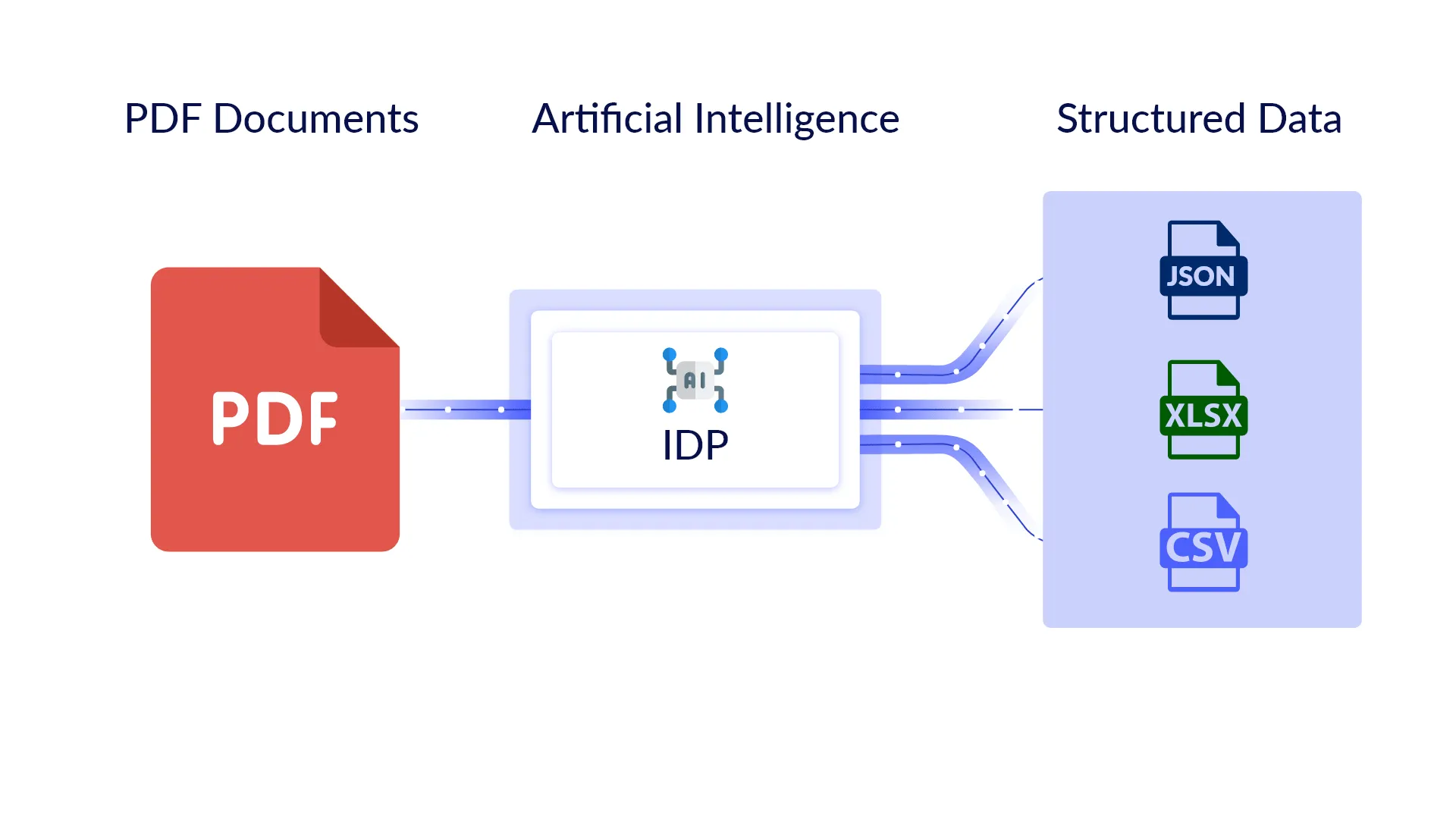
Intelligent Document Processing is the next-generation automated data extraction technology that can capture information from structured, semi-structured, and unstructured documents such as Gmail for email text, PDF, or different scanned documents. It then classifies and extracts relevant data for further processing using AI technologies.
Leading IDP solutions utilize deep learning and machine learning technology along with AI to enhance the quality of data extraction. IDP solutions are able to enhance the quality of sub-standard scanned documents with the noise reduction feature. They can auto-classify different document types received, extract data, and validate it against predefined set of rules to ensure the maximum accuracy.
The best part about IDP solutions is that they can be seamlessly integrated with your existing systems and other automation platforms. IDP enjoys a wide variety of use cases across several business functions such as claims processing, record management compliance, and client onboarding.
OCR merely transcribes a document and provides you with a text representation of the image but fails to provide the necessary content for downstream processes. Another domain where OCR exhibits shortcomings is its incompatibility with various document types. Whereas an IDP solution able to extrapolate the business data from a document and provide context for further analysis.
Here is a comprehensive comparison of how both OCR and IDP interpret document types and yield final output to the user -

A PDF invoice is machine-generated, that contains printed text and is commonly seen in a company when dealing with relevant credentials. Here is how it gets transcribed via OCR and IDP -

Often application forms are filled out in sloppy handwriting and marginally skewed when banks received them for processing. Here is how these forms get transcribed via OCR and IDP -
Checks must get transcribed with greater accuracy as it involves financial matters. Here is how it gets transcribed via OCR and IDP -
Here is a brief layout that summarizes the various distinctions between OCR and IDP:-
If you are processing hundreds of template-based simple documents with almost no variation in the layout, traditional OCR solution is the answer. However, if there's a level of complexity involved with the documents or you need a complete automated solution for document processing, IDP is the right option for you.
If you're reading this article, chances are IDP is the right solution for you, however, if you're still not sure about the choice you want to make, you can always schedule a free demo with us. This will not be a sales call but an attempt to understand your industry use-case and lead your way!
.webp)